Knowledge Base
Possible interview questions.
Interview questions for probability and statistics.
Can you give an intuitive definition of probability of an event?
Intuitively, probability is the measure of how likely an event is to happen, a value between 0 (impossible) and 1 (certain), often expressed as a fraction or percentage, representing the proportion of times an outcome occurs over many repetitions of an experiment, like a coin landing on heads roughly half the time in many flips.
What is the absolute necessery condition for the intuitive definition of probability to be true?
The intuitive definition of probability (classical/frequentist) says it's the ratio of favorable outcomes to total possible outcomes (P(E) = Favorable/Total). The crucial condition for this simple formula to work is that all possible outcomes must be equally likely (equally probable).
What is the difference between probability and statistics?
Probability tells you how to go from a population to a sample, and statistics tells you how to go from a sample to a population. So if one has a bin with red and blue balls and takes a number of balls from it, statistics estimates how many blue and red balls there could be in the bin. The probability estimates how likely it is that you take specific number of blue and red balls knowing the number of it in the bin.
Enlist and explain the most important combinatoric formulas.
- Number of possible permutations to arrange distinct objects:
Consider 5 balls of different colors, how many ways are there to put it on a table near each other on a line?
- Permutations with replacement:
How to order r distinct, independent objects with n options for each object (how many outcomes are there throwing r = 6 dies with n = 6 faces).
- Permutations without replacement:
How to order r samples out of n distinct objects (how many ways are there to take r = 5 cards out of a deck with n = 52 distinct cards).
- Combinations with replacement:
Choose r distinct objects with n options, where order of the objects does not matter, but options of the objects can repeat (choosing 2 ice-cream scoops out of 3 flavors, but scoops can be of the same flavor ).
- Combinations without replacement:
Choose r samples out of n available (like choose r = 3 persons from a group of n = 5 people, a person can not be chosen twice).
How is probability generally defined in terms of sets?
Let be a sample space, - an event or a subset from the sample space, then probability is a function defined between 0 and 1 describing how likely it is for the event to come. Probability function must sutisfy following rules:
- , and
- For disjoint events and , the probability of an overlapping event is a sum of the probabilities of the separate events:
How to express a possible outcome or element of a sample space in terms of sets?
Let be a possible outcome or an element of a sample space :
What are the differences between "element of", "subset" and "proper subset"?
- - "subset" means every element of a set is also in another set and these sets may be equal, e.g.:
- - "proper subset" means every element of a set is also in another set, but they are not equal, e.g.:
- - "element of" means an object is an element of a set, e.g.:
A set can also be an element of another set, but only as a single element and not as a combination or permutation of another single elements, e.g:
What is the difference between union and intersection of two sets?
- - union, means that elements are in A, or in B, or in both sets, e.g.:
- - intersection, means that elements are in A and B, e.g.:
What is the probability of the union of two non-disjoint event sets?
Addition rule of probability, or inclusion exclusion formula:
How to calculate a probability that an event won't happen, knowing its probability to happen?
Because the probability of a sample space is 1 and if we know the probability of an event to happen, we can calculate the needed probability as follows:
What is conditional probability of two events and how it is calculated? Give a simple example.
The conditional probability of an event A given event B is written as:
and is defined by:
where .
Imagine a sample space S as a big rectangle (all possible outcomes).
- Let's draw set B as a circle inside S, meaning all outcomes where event B happens.
- Let's draw set A as another circle, meaning all outcomes where A happens.
- The intersection of the circles represents outcomes where both A and B happen.
Now, if one knows that B has happened, the subsets are restricted to B. One ignores everything outside B and wants to know how much of B is also in A, which is the overlap of two events and rerpesents conditional probability.
Let's consider 100 students:
- 40 are in club A
- 50 are in club B
- 20 are in both A and B
Then, the probability that a student from club A is also in club B:
What is Bayes' rule?
Bayes' rule describes connection between conditional probabilities of two events:
Which follows from the definition of the probability of the intersection of two events:
Which in turn follows from the definition of conditional probability.
Define the law of total probability.
The law of total probability allows to compute the probability of an event A by breaking the sample space into disjoint cases (events that do not overlap) that together cover all possibilities. If is a partition of the sample space S (disjoint events that sum to the whole space, ), then:
What is the difference between prior and posterior probabilities?
The prior probability of an event is the initial belief about the event before observing any new evidence. It’s what is known or assumed before seeing data. The prior probability is defined by . The posterior probability is the updated belief about an event after observing evidence. It is defined by conditional probability .
When are two events independent?
Two events are independent when the probability of their intersection is equal to the multiplication of their prior probabilities:
Which is equivalent to the following:
How is independence of many events defined?
Infintely many events are said to be independent if any finite subset of them is independent. It means that the probabilities of the intersections of the finite subsets is defined by multiplication of their prior probabilities (pairs, triplets, quadruplets and so on).
What is conditional independence?
Events A and B are conditionally independent given E if the following is true:
Give a definition of random variables.
A random variable is a function that assigns a numerical value to any possible outcome from a sample space of an experiment, e.g. an experiment with two coin tosses:
Sample space is , now define , , and , where variable represents number of heads in a series of two coin tosses.
What is a distribution of a random variable?
Distribution of a random variable specifies the probability of all events associated with it.
Name two main types of random variables.
There are two main types of random variables discrete and continuous.
Give a formal definition of a discrete random variable.
A random variable X is discrete if there exists a finite or countable set such that for each and .
What is support of a discrete random variable?
It is a finite or countable set of values, where the probability of a variable taking these values is bigger then zero.
What is probability mass function of a discrete random variable?
The probability mass function of a discrete random variable X is a function that gives probability of the variable to take value from its support.
Give a formal definition of the Bernoulli distribution.
A random variable is said to follow a Bernoulli distribution with parameter , where , if probability mass function (PMF) is , for . Here represents success with probability and represents failure with probability . A Bernoulli distribution models a single binary experiment with success probability .
What is an indicator random variable?
An indicator random variable is a function that takes value 1 when a given event occurs and 0 otherwise. It is a Bernoulli-distributed random variable with parameter equal to the probability of the event.
What is Bernoulli trial?
A Bernoulli trial is a single random experiment with exactly two possible outcomes, usually called success and failure, where the probability of success is fixed.
Give a formal definition of Binomial distribution.
A random variable is said to follow a Binomial distribution with parameters and if it represents the number of successes in independent Bernoulli trials, each with success probability . It is denoted by . A Binomial distribution models the number of successes in a fixed number of independent Bernoulli trials with the same success probability. The PMF of the Binomial distribution is defined as:
for . The first part of the PMF represents the number of combinations for successes out of trials and we are not interested in the order of the sucesses.
Here is the visualization of some Binomial distributions:
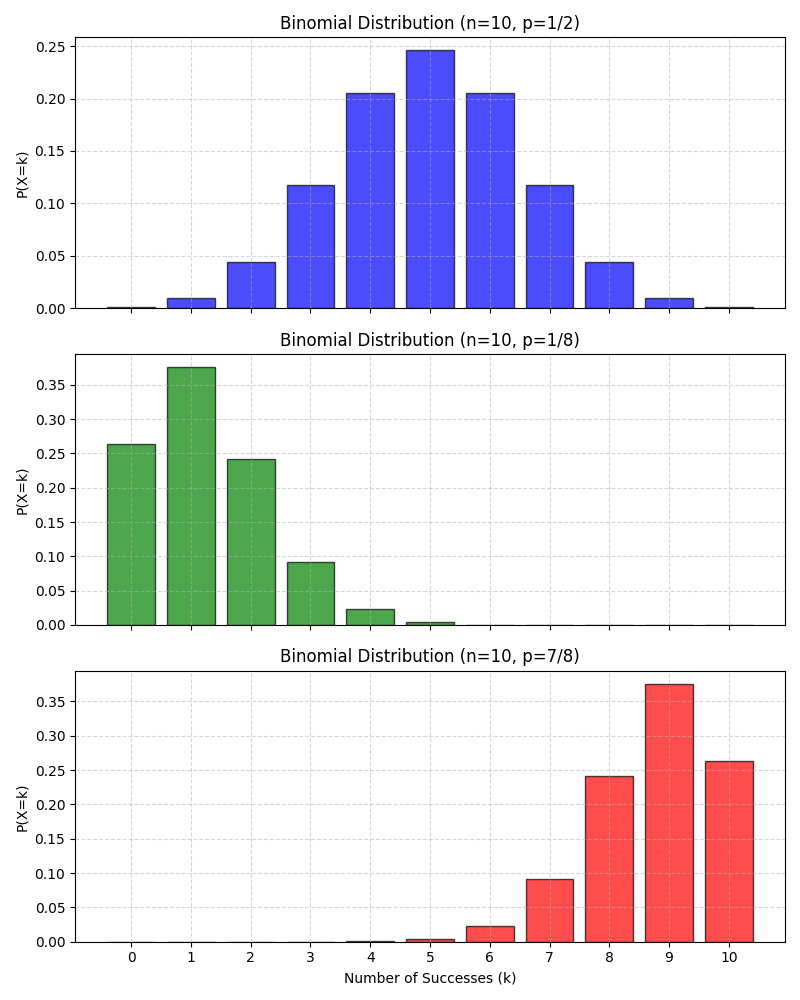
Give a formal definition of Hypergeometric distribution.
A discrete random variable has a Hypergeometric distribution if it counts the number of successes in a sample of size drawn without replacement from a finite population of size containing exactly successes. It is denoted by , where is the total population size, is the total number of sucesses in the population, - number of draws and - number of sucesses in the sample.
The PMF of the Hypergeometric distribution for is defined by:
where:
- - number of ways to choose sucesses out of available successes.
- - number of ways to choose remaining failures out of available.
- - number of total ways to choose elements out of available.
Here are plots of some Hypergeometric distributions: 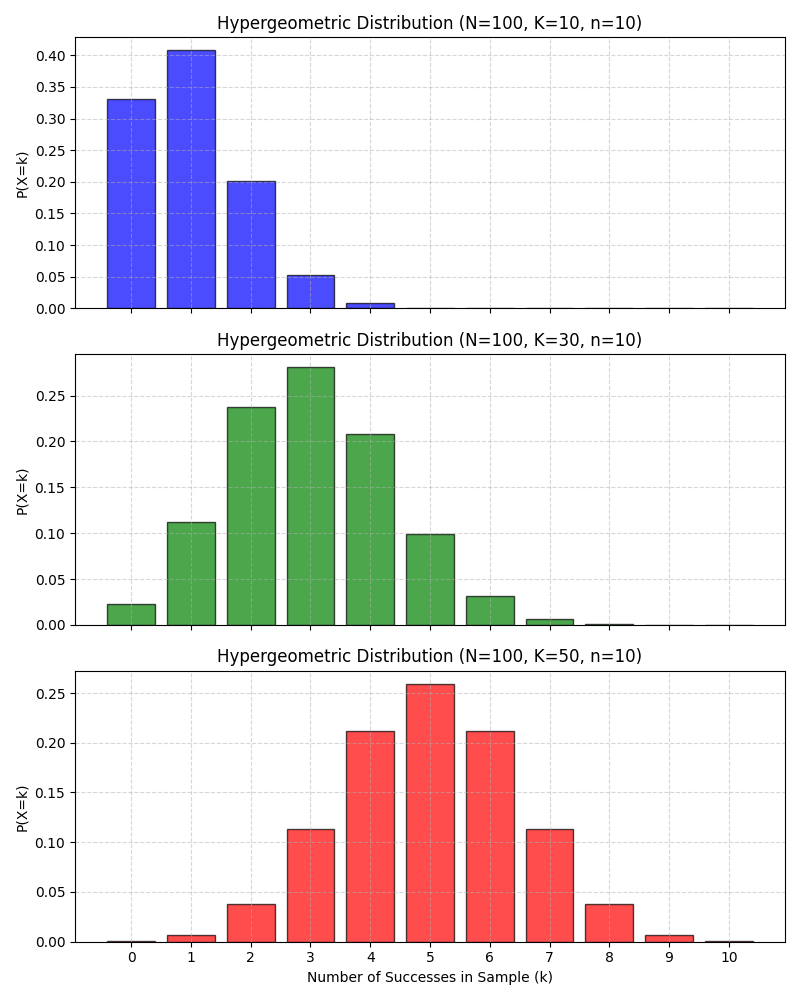
Is there connection between Binomial and Hypergeometric distributions?
The binomial can actually be seen as a limit or approximation of the hypergeometric under certain conditions.
| Binomial | Hypergeometric |
| Independent trials | Dependent draws |
| Sampling with replacement | Sampling without replacement |
| Infinite or very large population | Finite population |
| Constant success probability | Changing success probability |
When the population is very large compared to the sample size, sampling without replacement behaves almost like sampling with replacement.
Give a formal definition of a discrete uniform distribution.
A discrete random variable is said to have a discrete uniform distribution over a finite set of values if each value is equally likely.
for .
What is Cumulative Distribution Function (CDF)?
For a random variable the CDF is a function , for all .
Enlist and explain key properties of a CDF.
- Non-decreasing: If , then
- Right-continuous: at the points of jumps CDF is continuous from the right part.
- Convergent to 0 and 1 in the limits:
- Probability recovery:
How are PMF and CDF of a discrete random variable related?
The relation between PMF and CDF of a discrete random variable can be described as:
Here are the plots of PMF and CDF for : 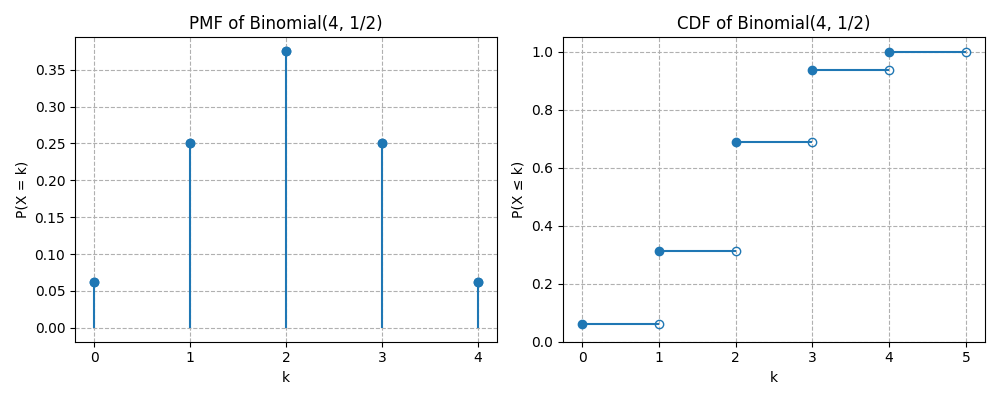
Give a formal definition of a function of random variables.
A function of a random variable is a new random variable , defined by applying deterministic function to :
And formally for any outcome :
How to calculate PMF of a function of a random variable?
For a discrete random variable an , the PMF of is given by:
Here probabilities of all values of that map to the same are summed. For example lets consider a square function of a die roll:
- is die roll outcome with PMF , for
- values are 1,4,9,16,25,36
- The PMF of can be calculated as:
Define when two random variables are independent.
Two random variables and are independent if:
What is the distribution of the sum of two independent variables with binomial distributions?
If and and they are independent, then:
Give a definition of conditional independence of two random variables given a third random variable.
Random variables and are conditionally independent given a random variable for all and in support of if:
What is expectation of a discrete random variable?
Expectation or mean value of a discrete random variable is defined as a weighted average:
How do expectations of two random variables with the same distribution relate to each other?
Expectations of two random variables with the same distribution are equal.
How is the expectation of a sum of two random variables or a product of a constant and a random variable defined?
Due to linearity of expectations, these values for any random variables and and a constatnt are defined as:
and
How is monotonicity of expectation is defined?
For two random variables for which the enaquality is true with probability 1, the expectation relation is as follows: , where equality holds only if with probability 1.
What is Geometric distribution of a discrete random variable?
Let be a sequence of independent and equaly distributed Bernoulli trials with
Define the random variable
Then is said to have a geometric distribution with parameter , denoted by:
The variable counts the number of trials until first success which occurs with a probability for each trial. The PMF of geometric distribution is defined for by:
The geometric distribution is memoryless:
The expectation for this distribution is:
Here are some plots of Geometric distributions for different probabilities: 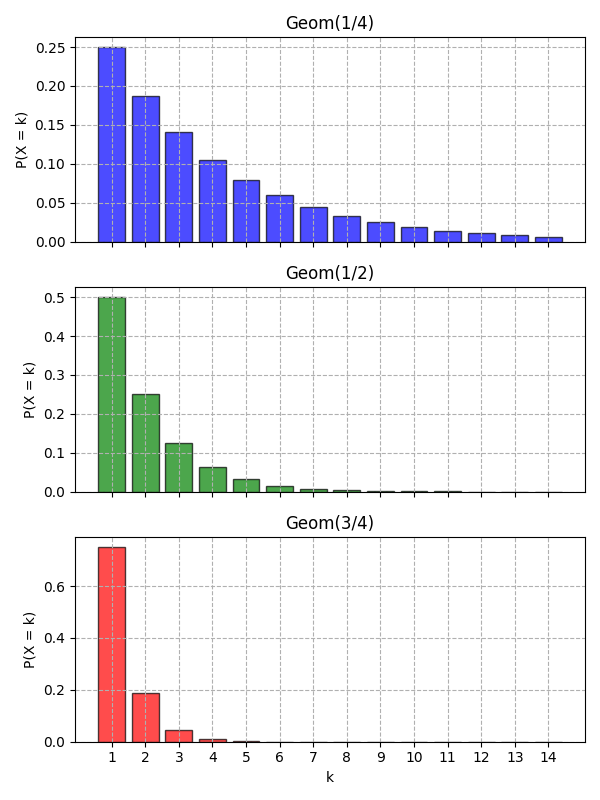
Give a formal definition of the Cumulative Distribution Function of Geometric distribution.
The CDF of a discrete random variable with distribution is defined for by:
Here is a plot of PMF versus CDF of Geometric distribution: 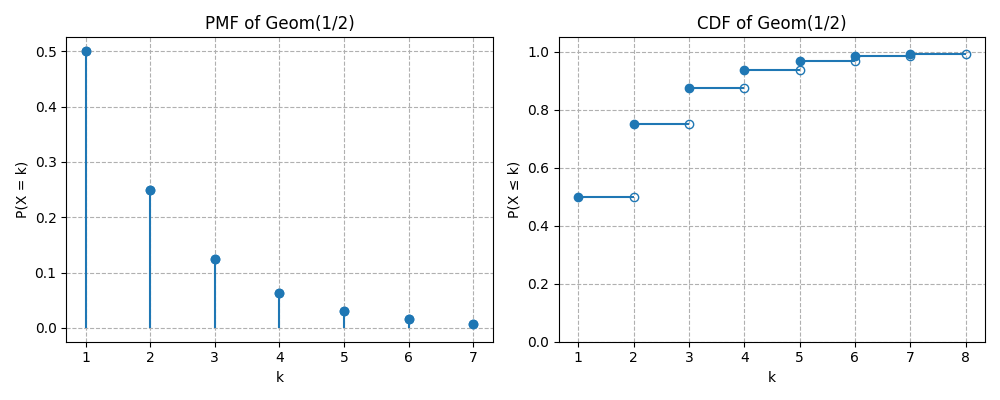
How is the Negative Binomial distribution defined?
If a random variable counts the number of trials to get -th success in a series of independent Bernoulli trials, then the variable has the Negative Binomial distribution, which is denoted by:
where is the probability of success.
How does PMF of the Negative Binomial distribution look like?
For the PMF of the Negative Binomial Distribution is defined by:
How is the Expectation of the Negative Binomial distribution defined?
The expectation of a random variable with the Negative Binomial distribution is defined by:
What are the main properties of indicator variables?
- for any positive integer
How is the Fundamental Bridge between probability and expection defined?
The probability of an event is the expected value of its indicator variable:
Give the formal definition of the Low of Unconcious Statistician (LOTUS).
If is a discrete random variable and is a function of real numbers, then:
Define the Variance of a discrete random variable.
The variance of a discrete random variable is given by:
Or an equivalent formula:
where
with be the PMF of .
What are the main properties of Variance?
Non-negativity:
.Translation invariance:
, for any constant .Scaling property:
, for any constant .Additivity for independent random variables and :
Give the formula of the variance of a discrete random variable with Binomial distribution.
If , then the variance of such variable is given by:
Give the formula of the variance of a discrete random variable with Hypergeometric distribution.
If , then the variance of such variable is given by:
Give the formula of the variance of a discrete random variable with Negative Binomial distribution.
If , then the variance of such variable is given by:
Give the formula of the variance of a discrete random variable with Geometric distribution.
If , then the variance of such variable is given by:
Give a formal definition and interpretation of Poisson distribution.
Let be a fixed real number. A discrete random variable is said to have a Poisson distribution with parameter , denoted:
if its PMF is defined as:
The Poisson distribution models the number of occurrences of events in:
- a fixed interval of time, area, volume, or space,
- when events occur independently,
- at a constant average rate ,
and cannot occur simultaneously.
Examples:
- Number of emails arriving in one hour.
- Number of radioactive decays per second.
- Number of customers entering a store in a day.
Here are the plots of PMF and CDF of : 
How is the expectation of Poisson distribution is defined?
If , then its expectation is given by:
How is the variance of Poisson distribution is defined?
If , then its variance is given by:
How is the sum of two independent Poissons defined?
If and and independent of then:
How is the conditional distribution of a variable with Poisson distribution given a sum with another independent variable with Poisson defined?
If and and independent of , then the conditional distribution of given is .
How are Binomial and Poisson distributions related?
If with and such that remains finite, then can be approximated by .
Give a formal definition of a continuous random variable in terms of distribution.
A random variable has a continuous distribution if its CDF is differentiable. The function is allowed to be continuous but not differentiable at the end points as long as it differentiable at the rest of the points.
What is the main difference between discrete and continuous variables in terms of probability?
For a continuous random variable the probability in contrast to a discrete random variable. One can only define probability of a continuous random variable to fall into some range of values.
What is the Probability Density Function of a continuous random variable?
The probability density function (PDF) of a continuous random variable is defined by derivative of the CDF of this variable. The support of the variable is the set of all , where . The CDF itself is not a probability and it must be integrated for a range of values in order to calculate probability that a corresponding random variable falls into this range.
How to calculate CDF from PDF of a continuous random variable?
The CDF of a continuous random variable can be calculated from PDF as follows:
Which criteria must be sutisfied by a function to be a valid PDF?
In order to be a valid PDF a function must be:
- Non-negative:
- Integrate to 1:
How is the expectation of a continuous random variable defined?
The expectation, or mean value of a continuous random variable is defined as follows:
It can be thought of as a balancing point of a continuous distribution. The expectation in this case has also the property of linearity as for discrete variables.
Define the Low of the Unconcious Statistician (LOTUS) for continuous random variables.
If is a continuous random variable and is a function of real numbers, then:
Give a formal definition of the Continuous Uniform distribution.
A continuous random variable has a Uniform distribution on the interval , where , if its PDF is
The CDF of the Uniform distribution is defined as:
Here are the plots of PDF and CDF of : 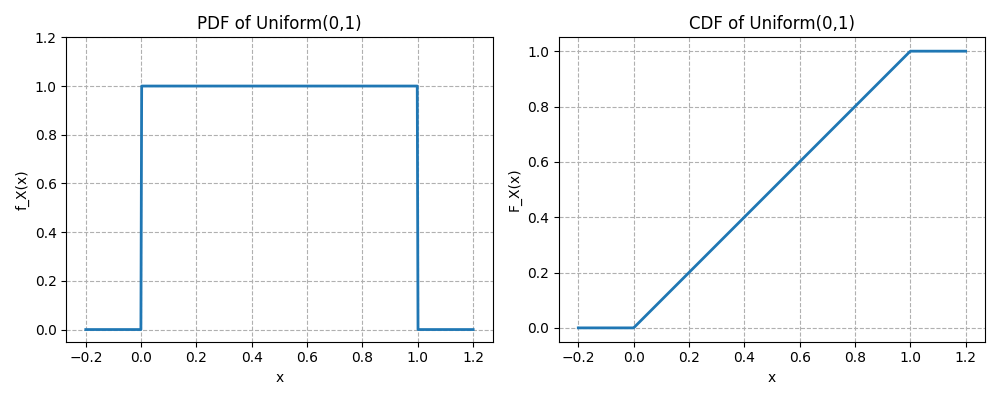
How is the Expectation of the continuous Uniform distribution defined?
The expectation of a random variable is defined as follows:
How is Variance of the continuous Uniform distribution defined?
The variance of a random variable is defined as follows:
Give a formal definition of the Standard Normal Distribution.
A continuous random variable is said to have the standard normal distribution if its PDF is
How does the CDF of the Standard Normal distribution is defined?
The CDF of the standard normal distribution is defined as:
Here are the plots of PDF and CDF of the standard normal distribution: 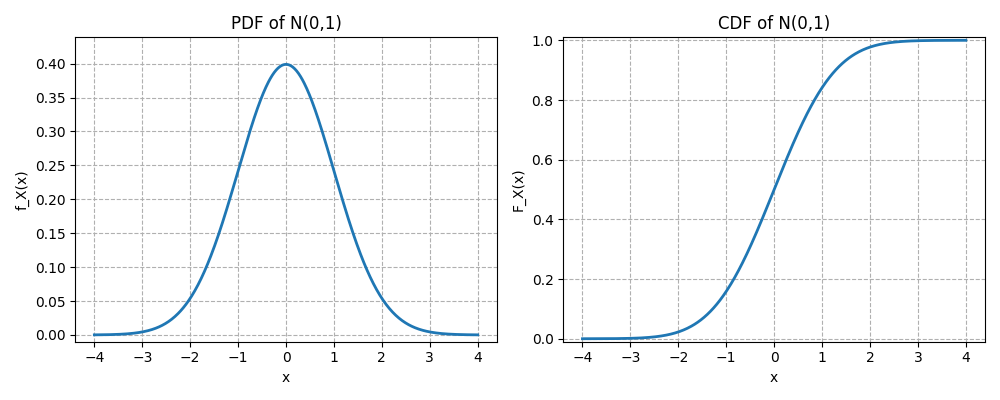
Give the values of the expectation and variance of the Standard Normal Distribution.
The expectation of the standard normal distribution is and the variance is .
Give the formal definition of the Normal Distribution.
A continuous random variable is said to have a normal distribution with parameters mean and variance , denoted by , if its PDF is
How is the CDF of the Normal distribution is defined?
The CDF of the normal distribution is defined as:
Give a formal definition of the Exponential distribution.
A continuous random variable is said to have an exponential distribution with a rate parameter , denoted by , if its PDF is
The exponential distribution models the waiting time until the first event in a process where events occur continuously and independently at a constant average rate.
How is the CDF of the Exponential distribution defined?
The CDF of the exponential distribution is defined as
Here are the plots of PDF and CDF of the exponential distribution: 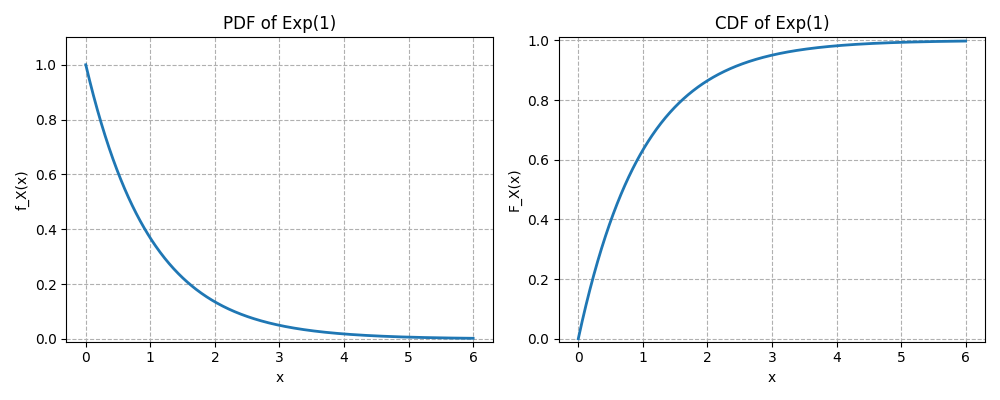
How does Expectation of the Exponential distribution look like?
The expectation of the exponential distribution is defined as:
How does Variance of the Exponential distribution look like?
The variance of the exponential distribution is defined as:
What does memoryless property of a continuous distribution mean?
A continuous variable with support is said to be memoryless, if for all ,
The future does not depend on the past.
Which distribution does a memoryless continuous variable have?
If is a positive continuous random variable with memoryless property, then it has an exponential distribution.
Give a formal definition of a Poisson process.
A process of events occuring in continuous time is called a Poisson process with the rate , if two conditions hold:
- The number of occurances that take place in an interval of length is a random variable with distribution.
- The number of occurances in disjoint intervals are independent of each other.
How are interarrival times in a Poisson process defined?
An interarrival time in a Poisson process is the waiting time between the -st and -th event. E.g. is the time until the first event, - is the time between the first and the second event, etc. The interarrival times in a Poisson process have Exponentioal distribution and are independent of each other. The average waiting time is .
Give a formal definition of the Mean value of a distribution.
The mean value, or the center of mass of a distribution is defined by the expectation of the distribution (weighted average).
Give a formal definition of the Median value of a distribution.
Let be a real valued random variable. A real number is called median of distribution of if
and
Give a formal definition of the Mode value of a distribution.
For any real valued random variable , a real number is called mode value if it maximizes the PMF in a discrete case, and the PDF for continuous variable, for all .
What is the Skewness of a distribution.
The Skewness of a real-valued random variable with mean value and standard deviation is the third standardized moment of a distribution, which is defined as:
Which summary values are more appropriate for symmetric and non-symmetric distributions.
For non-symetric distributions mean and standard deviation values are missleading and median and interquartile range should (IQR) be used for skewed distributions. For a distribution with several peaks (multimodal distribution) mode value and intermodal spread (standard deviation within a peak) should be used.
Give a formal definition of interquartile range (IQR).
Let be a real-valued random variable with CDF . Define:
- the first quartile (lower quartile):
- the third quartile (upper quartile):
The interquartile range is defined as:
Give a formal definition of the Kurtosis of a distribution.
The Kurtosis of a real-valued random variable with mean value and standard deviation is the fourth standardized moment of a distribution, which is defined as:
Kurtosis measures the weight of the tails and the frequency of extreme deviations relative to a normal distribution. High Kurtosis (heavy tails) implies more frequent outliers and thus higher probability of extreme events. Lower Kurtosis means that the data are more evenly spread and thus there are fewer extreme values.
Give a formal definition and interpretation of a Moment Generating Function.
Let be a real-valued random variable. The Moment Generating Function (MGF) is:
defined for all real numbers in an open interval containing for which the expectation exists (is finite). The MGF generates moments of a distribution by differentiation:
E.g. mean value can be calculated from the MGF by first derivative. The MGF can be used to define the sum of two independent random variables as:
If the MGF exists in a neighborhood of , it uniquely determines the distribution of .
Example:
For X~Bern(p), the MGF is: .
Give a formal definition of joint CDF of two discrete random variables.
The joint CDf of two discrete random variables and is the function given by:
For variables the joint CDF is defined analogously.
Give a formal definition of joint PMF of two discrete random variables.
The joint PMF of two discrete random variables and is the function given by:
For variables the joint PMF is defined analogously. In order the function to be valid the following must be true:
What is the marginal PMF of two discrete random variables?
For two discrete random variables and the marginal PMF of is:
How is the conditional PMF of two discrete random variables defined?
For two discrete random variables and the conditional distribution PMF of given is
It is seen as a function of for fixed .
How is the joint PDF of two continuous random variables defined?
If two random variables and are continuous with joint CDF , their joint PDF is the derivative of the joint CDF with respect to and :
In order the joint PDF to be valid it is required it to be positive and integrate to 1.
How is the marginal PDF of two continuous random variables defined?
For two continuous random variables and with joint PDF , the marginal PDF of X is:
How is the conditional PDF of two continuous random variables defined?
For two continuous variables and with joint PDF the conditional PDF of given is
for all with .
How is the 2D LOTUS defined?
Let be a function from to . If and are discrete then the expectation of this function is:
For continuous case the expectation of the function is defined as follows:
Give a formal definition of the Covariance between two random variables.
The covariance between two random variables and is:
The two variables with zero covariance are independent and thus uncorrelated.
Emlist the main properties of Covariance.
- .
- .
- , for any constant
- , for any constant .
- .
- .
- . For : .
How is Correlation between two random variables defined?
The correlation between two random variables and is defined as:
Correlation is defined between and .
Give a formal definition of Multinomial distribution.
Let be the number of independent trials and let
be a probability vector, such that
A random vector
is said to have Multinomial distribution with parameters and , written
if is a number of outcomes of category in independent trials, where each trial results in one of the categories with probabilities .
How is the joint PMF of Multinomial distribution is defined?
For non-negative integers , such that:
the joint PMF is
Define multinomial conditioning.
If then
where .
Define Covariance for Multinomial distribution.
Let , then for , .
Give a formal definition of the Multivariate Normal distribution.
A vector of rundom variables is said to have multivariate normal distribution if every linear combination of its components has a Normal distribution.
How is the joint PDF of the Multivariate Normal distribution defined?
Let be an n-dimensional rundom vector with mean vector and covariance matrix , then is said to have Multivariate Normal distribution if its joint PDF is defined as:
where:
- is the determinant of the covariance matrix
- is symmetric and positive definite.
How is the joint Moment Generating Function defined?
Let be an n-dimensional rundom vector. The joint moment generating function of is the function:
if the expectation exists in a neighborhood of .
- Here .
Give a formal definition of the Beta Distribution.
Let be a continuous random variable defined on the interval . It is that has a Beta bistribution with parameters and , written
if its PDF is defined as:
where is the Beta function, defined as
Give a short interpretation of Beta Distribution.
- Shape flexibility:
- Beta distribution is bounded between 0 and 1
- Its shape depends on and values:
- -
- , - bell-shaped
- , - U-shaped
- , - skewed right
- , - skewed left
- Probability Interpretation: Often used to model random proportions, e.g., fraction of successes in Bayesian inference.
Give definitions for mean, variance and mode values of the Beta distribution.
- Mean:
- Variance:
- Mode (if ):
Give some examples of usage of Beta distribution.
- Bayesian posterior for a Bernoulli parameter p (Beta prior).
- Modeling proportions, probabilities, or rates between 0 and 1.
- Random variables constrained in a finite interval.
Give a formal definition of the Gamma Distribution.
Let be a continuous random variable with support . One says has a Gamma distribution with shape parameter and rate parameter , written
if its PDF is defined as
where is the Gamma function defined as
Give a short interpretation of the Gamma distribution.
Waiting time:
If events occur according to a Poisson process with rate , then is the time until -th event and has Gamma distribution .Sum of exponential variables:
If are independent, identically distributed variables and , then
Give definitions for mean, variance and mode values of the Gamma distribution.
- Mean:
- Variance:
- Mode (if ):
How are Beta and Gamma distributions connected?
The Beta distribution can be constructed from Gamma distributions. Let and be two independent random variables with the same rate . Define
Then:
and
Moreover, is independent of . And the normalization constant of the Beta distribution can be defined as
Give a formal definition of a Conditional Expectation given an event.
Let be an event with non-zero probability. If is a random variable then conditional Expectation in a discrete case is defined as
And for continuous case
where the conditional PDF is defined as follows:
How is the Low of Total Expectation defined?
Let be partition of events with non-zero probability from a sample space. Let be a random variable with support in this sample space. Then
is a total expectation of variable .
Give a definition of Conditional Expectation given a random variable.
If we have a function , then the conditional expectation of given , denoted is defined as a random variable . It means if takes the value of then becomes .
Enlist the properties of Conditional Expectation.
- If and are independent, then .
- For any function , .
- Linearity: and for any constant .
- Adam's low: .
- The random variable is uncorrelated with for any function .
Define the Conditional Variance.
The conditional variance of given is
which is equivalent to
Give a definition of the law of the total variance (Eve's law).
The law of the total variance is defined by the following formula:
Give a definition of Couchy-Schwarz inequality for marginal bound on a joint expectation.
For any random variables and with finite variances the following inequality is true:
Give a definition for Jensen's inequality for convexity.
Let be a random variable with existing finite expectation value. If a function is convex, then
Equality holds here only if:
- all are equal, or
- is linear on a convex hull of
Give a definition for Markov's bound on tail probabilities.
For any random variable and a constant ,
If frequently takes large values (i.e. large tail probability), then its expected value must also be large.
Give a definition for Chebyshev's bound on tail probabilities.
Let a random variable have mean and variance , then for any positive non-zero constant
Give a definition for Chernoff's bound on tail probabilities.
For any variable and constants and ,
Give a formal definition of the Weak Law of Large Numbers.
Let be independent and identically distributed random variables with sample mean and sample variance . Then for all
Give a formal definition of the Strong Law of Large Numbers.
Let be independent and identically distributed random variables with sample mean and sample variance . Then for sample mean
Give a formal definition of the Central Limit Theorem.
Let be independent and identically distributed random variables with sample mean and sample variance . Then with
where is the Standard Normal distribution.
Give a formal definition of the Chi-Square distribution.
Let be independent standard normal random variables, i.e. . The random variable
is said to have a Chi-Square distribution with degrees of freedom, denoted as . For it has the following PDF:
and for the function is zero. The Chi-square distribution is a special case of the Gamma distribution .
Give a formal definition of the Student-t distribution.
Let be a standard normal random variable, a chi-square distributed random variable with degrees of freedom and both are independent. Then the random variable
is said to follow a Student-t distribution with degrees of freedom, denoted by
The PDF of Student-t distribution for is defined as
The key properties of the Student-t distribution are as follows:
- Support: .
- Symmetry: symmetric about 0.
- Mean: for .
- Variance: for and for .
- Heavy tails: heavier tails than the normal distribution.
- Limit: as .
Give a formal definition of a Markov chain.
A sequence of random variables taking values from a state space is called Markov chain, if for all positive non-zero values of the following is true:
The quantity is called transition probability from the state to .
Give a definition of the Transition Martrix of a Markov Chain.
Let be a Markov chain with a state space and let be the transition probability from the state to . The matrix is called the transition matrix of the chain.
Give a formal defintion of -step transition probability.
The -step transition probability from the state to is the probability of being in the state after exactly transitions after being at . It is denoted by :
Note that
since the transitions and are independent due to Markov chain property.
What are recurrent and transient states in Markov chains?
State of a Markov chain is recurrent if starting from the probability of the chain returning to the state again is 1. Otherwise the state is transient, which means there is a positive probability of chain never returning to that state. Number of returns to a transient state has a Geometric distribution.
How are irreducible and reducible Markov chains defined?
A Markov chain with a transition matrix called irreducible if for any two states and there is a positive probability of getting from state to in a finitie number of steps. It means that for any two states and the entry of the transition matrix is positive. The Markov chain that is not irreducible is called reducible. In an irreducible Markov chain with finite state space all states are recurrent.
How is a period of a state in a Markov chain defined?
The period of a state i is defined as a great common divisor of all possible return times back to the state . If the period of a state is 1 the state is called aperiodic, which happens for states with self loops. In an irreducible Markov chain all states have the same period.
What is stationary distribution of a Markov chain?
Consider a Markov chain with finite or countable state space and transition matrix . A probability distribution is called stationary if
for all , with normalization condition
The main properties of the stationary distribution are:
- Stationary distribution is marginal, not conditional.
- For any irreducible Markov chain, there exists a unique stationary distribution.
- For an irreducible, aperiodic Markov chain with stationary distribution the transition matrix converges with to a matrix where each row is .
- For an irreducible Markov chain with stationary distribution , the value of is a reciprocal of an expected time to return to the state .
What is reversibility of a Markov chain.
Let be the transition matrix of a Markov chain. Let there be with and such that
for all and , then this equation is called reversibility condition and the Markov chain is called reversible. If the condition satisfies, then is the stationary distribution. If each column of the transition matrix sums to 1, then the Uniform distribution over all states is a stationary distribution of this Markov chain.
What problem does a Markov Chain Monte-Carlo Simulation solve?
Suppose you want to sample from a target distribution .
Example situations:
- A complicated posterior distribution in Bayesian inference.
- A high-dimensional distribution where normalization is unknown.
Often the distribution can only be computed up to a constant:
If direct sampling is hard a Monte-Carlo simulation can create a Markov's chain whose long-run distribution equals . Some MCMC algorithms are Metropolis-Hastings and Gibbs sampling.
Explain Metropolis-Hastings MCMC algorithm.
The core idea of the Metropolis-Hastings MCMC algorithm is:
- Start from a current state
- Propose a new candidate state
- Accept or reject the candidate based on a probability rule.
Over time, the chain produces samples approximating the target distribution.
The algorithm steps are as follows:
- Choose a starting point .
- Draw a new candidate state from a proposed distribution :
Common examples of proposed distribution:
- Normal
- Uniform around the current value
- Compute acceptance probability:
- Sample from a and if the result is success accept the proposed state else stay in the actual state .
- Repeat many times.
After a burn-in period, the samples approximate the target distribution. The core strength of this method is that you do not need to know the normalization constant of the target distribution in order to conduct the simulation.
Explain the Gibbs sampling MCMC algorithm.
The Gibbs sampling algorithm is a special case of MCMC methods used to generate samples from a joint probability distribution when direct sampling is difficult but sampling from conditional distributions is easy. It is closely related to the Metropolis–Hastings algorithm, but it simplifies the acceptance step by always accepting proposals.
Suppose you want samples from a joint distribution:
Direct sampling might be hard, but you can sample from each conditional distribution:
Gibbs sampling generates samples by cycling through variables and sampling each one conditioned on the others.
The algorithm steps are as follows:
- Choose a starting point:
- Make sequential conditional sampling at iteration :
After one full cycle you obtain the next sample vector.
Give a definition of Poisson processes in one dimension.
A Poisson process in one dimension is a stochastic process that models random points occurring along a line (usually time) where events happen independently and at a constant average rate . The number of arrivals in a constant time has distribution. The numbers of arrivals in disjoint time intervals are independent.
Explain the conditioning property of one-dimensional Poisson processes.
Let be a Poisson process with rate . Suppose we condition on:
meaning exactly events occured in the time interval . Now take a smaller interval with .
Then:
In a Poisson process with the rate conditional on the joint distribution of the arival times is the same as the joint distribution of the order statistics of independent and equally distributed with random variables.
Explain the superposition property of one-dimensional Poisson processes.
Suppose we have independent Poisson processes:
with rates:
If we define a new process by adding the event counts:
then the rate of this process is the following sum:
Think of events coming from multiple independent sources:
phone calls from different departments
photons from different emitters
customers arriving through different doors
If each source produces events randomly at rate , then the combined stream of events is still random with rate equal to the sum of the rates.
Explain the thinning property of one-dimensional Poisson processes.
Let be a Poisson process with rate . Suppose that each event is independently kept with probability and removed with probability . Define a new counting process as a number of kept events. Then is itself a Poisson process with rate . Similarly, the removed events form another process with rate and the two processes and are independent Poisson processes.
Give a definition of two-dimensional Poisson processes.
Let denote the number of points in a region . A point process on the plane is a two-dimensional Poisson process with intensity if it satisfies:
Poisson distribution of counts:
For any bounded region ,where
- is the area of the region
- is the average number of points per unit area.
Independent counts in disjoint regions:
If are disjoint regions in the plane, thenare independent random variables.
Such properties of one-dimensional Poisson processes as conditioning, superposition and thinning are also valid for two-dimansional Poesson processes.
What is data reduction of a distribution in statistical inference?
In statistical inference, data reduction of a distribution refers to the process of summarizing the information contained in a full dataset in a smaller, simpler form that still retains all the relevant information for estimating the parameters of interest. Essentially, it’s about compressing the data without losing information needed for inference.
Let be a sample from a distribution with parameter and a function of the data. Data reduction is the process of replacing the full dataset with a statistic such that inference about can be based on instead of the full .
Example:
Let , then the statistic
contains all information about , so you can do inference using only the sum instead of all .
How is sufficient statistic defined?
A statistic containing all information about parameter is called sufficient if the conditional distribution of the sample given the value does not depend on . E.g. the summation statistic for a Poisson sample is sufficient, because it is a smallest summary of the sample containing all information about the parameter .
Explain what minimal sufficient statistic is.
In statistical inference, a minimal sufficient statistic is the most compressed statistic that still contains all the information about a parameter in the sample. It represents the maximum possible data reduction without losing any information relevant to the parameter.
Let be a sample from a distribution with parameter . A statistic is minimal sufficient for if it is sufficient, and for any other sufficient statistic , it can be written as a function of , e.g. sample mean and variance of a normal distribution.
Explain what ancillary statistic is.
An ancillary statistic is a statistic whose probability distribution does not depend on the unknown parameter of the model. So it contains no information about the parameter, even though it is computed from the data.
Let be a sample from a distribution with parameter .Let be a sample from a distribution with parameter . A statistic is ancillary if its distribution is independent of .
Formally:
does not depend on .
Example:
Suppose there are two random variables with normal distribution
Consider the statistic
If we standardize by variance
its distribution is and its independent of .
Explain what complete statistic is.
Let be a sample from a distribution with parameter . is complete if a function satisfies for all only if with probability 1. If the expected value of a function of is zero for every parameter value, then the function must be identically zero. There are no non-trivial unbiased functions of that vanish for all parameters. Completeness means that the statistic contains no hidden redundancy. If you try to construct a function of the statistic whose expected value is always zero, the only possibility is the trivial function. So the statistic is informationally tight: it does not allow cancellation of information across parameter values.
What is the likelihood function in statistical inference?
The likelihood function describes how plausible different parameter values are given the observed data. Suppose is a random sample from a distribution with parameter and probability density (or mass) function . After observing the data
the likelihood function is defined as
If the observations are independent, this becomes
- In probability theory: the parameter is fixed and data are random.
- In likelihood: the data are fixed, and the function of the parameter is viewed.
So the likelihood measures how well each parameter value explains the observed data.
Example:
Suppose
with known variance.
The density function is
The likelihood function is
This function tells us which values of make the observed data most likely.
Explain the principle of equivariance in statistical inference.
Let be a parameter and an estimator of based on a sample . Suppose we apply a transformation to the parameter, giving a new parameter
The principle of equivariance states that the estimator of the transformed parameter should be the same transformation applied to the estimator of . So if is an estimator of then the estimator of should be .
What is a point estimator in statistical inference?
A point estimator is a statistic used to estimate an unknown parameter of a population by a single numerical value based on sample data.
Let
be a random sample from a population with parameter . A point estimator of is a function of the sample observations:
The value obtained from the sample is called the point estimate.
Example:
If we want to estimate the population mean , the sample mean
is a point estimator of .
Explain method of moments (MOM) for point estimation.
This method equates sample moments with population moments.
Steps:
- Compute population moments in terms of parameters.
- Replace them with sample moments.
- Solve for the parameter.
Example:
If , then estimator is
Explain Maximum Likelihood point estimator (MLE).
This method chooses the parameter value that maximizes the likelihood function.
If the likelihood function is
then the estimator is the value that maximizes .
Example:
For a normal distribution
Explain Bayes point estimator.
In Bayesian inference, the parameter is treated as a random variable with a prior distribution . After observing data , we compute the posterior distribution:
where:
- is likelihood
- is prior distribution
- is posterior distribution
The Bayes estimator is the value that minimizes the expected posterior loss.
Let
- be a loss function
- be estimator decision
The Bayes estimator is
which means choose the estimate that minimizes the expected loss under the posterior distribution.
Different loss functions lead to different estimators.
- Squared Error Loss:
The Bayes estimator becomes the posterior mean:
- Absolute Error Loss:
The Bayes estimator becomes the posterior median.
- 0–1 Loss:
The Bayes estimator becomes the posterior mode, also called the MAP estimator (Maximum A Posteriori).
Explain principal difference between classical and Bayesian statistical inference.
The main difference between classical and Bayesian approaches in Statistical Inference concerns how the unknown parameter is treated.
In classical (frequentist) inference, the parameter is considered a fixed but unknown constant, and probability describes the randomness of the sample data. Inference is based only on the likelihood derived from the observed data.
In Bayesian Statistics, the parameter is treated as a random variable with a prior distribution representing prior knowledge. Using Bayes' Theorem, the prior is updated with the observed data to obtain the posterior distribution, which is then used for estimation and inference.
Enlist methods of evaluating the point estimators.
1. Classical Properties
- Unbiasedness - the estimators expected value equals the true parameter:
Which means there is no systematic over- or underestimation.
- Consistency – the estimator converges to the true parameter as sample size increases:
- Efficiency – among unbiased estimators, the one with smaller variance is more efficient. Often compared to the Cramér–Rao lower bound.
- Mean Squared Error (MSE) – combines bias and variance to measure error:
- Sufficiency – an estimator based on a sufficient statistic uses all information in the sample about the parameter.
- Robustness – the estimator’s performance is stable under deviations from model assumptions or in presence of outliers.
2. Loss-Function and Risk-Based Evaluation
- Loss function measures the penalty for estimating by .
Examples:- Squared error:
- Absolute error:
- 0–1 loss: 0 if correct, 1 if incorrect
- Risk function evaluates the expected loss:
- Optimality: an estimator is optimal if it minimizes the risk for the chosen loss function:
Example (Bayesian context):
- Squared error → posterior mean
- Absolute error → posterior median
- 0–1 loss → posterior mode (MAP)
Give a definition of what is hypothesis and its testing in inference statistics.
In Statistical Inference, a hypothesis is a statement or assumption about a population parameter that we want to evaluate based on sample data.
- Null hypothesis (): the default assumption, usually representing no effect or no difference.
- Alternative hypothesis (): represents the claim we want to test, usually indicating an effect or difference.
Hypothesis testing is the procedure of using sample data to decide whether to reject in favor of or not. It involves:
- Formulating hypotheses and .
- Selecting a test statistic that summarizes the evidence from the data.
- Determining the sampling distribution of the test statistic under .
- Computing the p-value or critical region to assess evidence against .
- Making a decision:
- Reject if evidence is strong.
- Fail to reject if evidence is insufficient.
Hypothesis testing does not prove true, it only evaluates whether data provide enough evidence to reject . Decisions are made with a predefined significance level (), controlling the probability of rejecting true .
Explain Critical Region / Rejection Region Method for Hypothesis testing.
In the frequentist framework, the Critical Region (or Rejection Region) Method is a way to perform hypothesis testing by defining a region of the sample space where, if the observed value of the test statistic falls inside, we reject the null hypothesis .
- The test statistic summarizes the sample data in a way that is sensitive to deviations from
- The critical region is determined using a significance level , which is the maximum probability of rejecting true .
Steps:
- Formulate and .
- Choose a test statistic suitable for the hypothesis and data type.
- Determine the sampling distribution of the statistic under .
- Define the critical value(s) based on the significance level .
- Compare the observed statistic to the critical value:
- If inside the critical region - reject .
- If outside - fail to reject .
Most common test statistics are:
- Z-test (Population Mean, known).
- t-test (Population Mean, unknown).
- Chi-Square Test (Variance or Goodness-of-Fit).
- F-test (Comparing Two Variances).
- Likelihood Ratio Test (General Parametric Models).
- Non-Parametric / Rank-Based Tests.
Explain the Z-test statistic for hypothesis testing.
A Z-test is a parametric hypothesis test used to determine whether a sample mean is significantly different from a hypothesized population mean. It is based on the standard normal distribution (), when the population variance is known or when the sample size is large () due to the Central Limit Theorem.
One-sample Z-test statistic:
Where:
- - sample mean.
- - hypothesized population mean.
- - population standard deviation (known).
- - sample size. Two-sample Z-test compares the means of two independent populations with known variances:
When to Use a Z-Test:
- Population variance is known.
- The sample is large.
- Data are continuous and approximately normally distributed (small samples).
- Testing means (one-sample or two-sample).
Example:
A factory claims that its light bulbs last hours on average. A quality control engineer takes a sample of bulbs and finds:
- Sample mean: hours.
- Known population standard deviation: hours. Test at significance level () whether the mean lifetime is less than hours.
Step 1: Define Hypotheses
- Null hyposethis: .
- Alternative hypothesis: .
Step 2: Choose Test Statistic
- One-sample Z-test:
Step 3: Compute the Test Statistic
Step 4: Determine Critical Value / Rejection Region
- Significance level: (one-tailed, left).
- Critical Z-value: (, the value of is taken from the normal distribution).
- Rejection region: .
Step 5: Make a Decision
- Observed falls in the rejection region.
- Decision: Reject .
Step 6: Conclusion
At 5% significance level, there is sufficient evidence to conclude that the mean lifetime of the bulbs is less than 1200 hours.
Explain the t-test statistic for hypothesis testing.
A t-test is a statistical test used to determine whether a sample mean is significantly different from a hypothesized population mean when the population standard deviation is unknown.
- It uses the Student’s t-distribution, which accounts for extra variability due to estimating from the sample.
- The shape of the t-distribution depends on the degrees of freedom (df = n – 1).
- As the sample size increases, the t-distribution approaches the standard normal distribution.
One-sample t-test statistic:
where:
- - sample mean.
- - hypothesized population mean.
- - sample standard deviation.
- - sample size.
Two-sample t-test (independent samples):
When to Use a t-Test:
- Population variance is unknown.
- The sample is small.
- Data are approximately normally distributed.
- Testing means (one-sample or two-sample).
Example: A nutritionist claims that the average sodium content in a certain brand of soup is 500 mg per serving. A random sample of 15 soups has:
- Sample mean: mg
- Sample standard deviation: mg Test at 5% significance level () whether the average sodium content differs from 500 mg.
Step 1: State Hypotheses
- Null hyposethis: mg
- Alternative hypothesis: mg
Step 2: Choose Test Statistic
- One-sample t-test is appropriate since is unknown and .
Step 3: Compute the Test Statistic
Degrees of freedom:
Step 4: Determine Critical Value / Rejection Region
- Two-tailed test at , which means splitting in each tail.
- From t-table:
- Rejection region:
Step 5: Make a Decision
- Observed falls in the rejection region.
- Decision: reject .
Step 6: Conclusion
At 5% significance level, there is sufficient evidence that the average sodium content differs from 500 mg.
Explain the Chi-Square test statistic for hypothesis testing.
A Chi-Square test ( test) is a non-negative test statistic used to evaluate hypotheses about:
- Variances of a normally distributed population.
- Goodness-of-fit: whether observed frequencies match expected frequencies.
- Independence or association in contingency tables.
The test statistic follows a Chi-Square distribution with degrees of freedom depending on the test type.
When to Use a Chi-Square Test
- Population variance test:
- You want to test : for a normal population.
- Goodness-of-fit test:
- Data are categorical, and you want to compare observed versus expected frequencies.
- Test of independence / association:
- You have a contingency table (e.g., row × column categories) and want to see if variables are independent.
- Assumptions:
- Data are independent observations
- For variance tests: population is normal
- For categorical tests: expected frequency per category ideally ≥ 5
1. Chi-Square Test for Population Variance.
Test Statistic:
Where:
- - sample size
- - sample variance
- - hypothesized population variance
- degrees of freedom:
Decision: reject if the statistic falls outside the critical values from table.
Example: Variance test
A machine claims to fill bottles with variance in volume of . A sample of bottles gives sample variance . Test at 5% significance level if variance is different.
Step 1: Hypotheses
Step 2: Test Statistic
- degrees of freedom:
Step 3: Critical Values (two-tailed, )
- Left:
- Right:
- Rejection region: , or
Step 4: Decision
- Observed does not fall in the rejection region.
- Decision: fail to reject
Conclusion: No sufficient evidence to say variance differs from 4 .
2. Chi-Square Test for Goodness-of-Fit
Test Statistic:
Where:
- - observed frequency for category
- - expected frequency for category
- - number of categories.
Degrees of freedom: , where is the number of estimated parameters of the samples distribution.
Example:
A die is rolled 60 times, yielding counts:
| Face | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Observed | 8 | 10 | 9 | 11 | 12 | 10 |
Test at if die is fair.
Step 1: Hypotheses
- die is fair, - die is not fair.
Expected frequency: for all faces.
Step 2: Test Statistic
Step 3: Degrees of Freedom
- ( because all faces are equally likely and there is no parameters to estimate).
- Critical value (, two-tailed is not needed for chi-squared, thus right tail test ):
Step 4: Decision
- Observed , thus fail to reject .
Conclusion: no evidance to suggest that the die is unfair.
3. Chi-Square Test for Independence (Contingency Table)
Test Statistic:
- degrees of freedom: df = (number of rows – 1) × (number of columns – 1)
- Decision: Reject if
The Chi-Square Test for Independence is used in Statistical Inference to determine whether two categorical variables are statistically independent or whether there is an association between them.
It is based on comparing:
- Observed frequencies (actual counts in the data)
- Expected frequencies (counts we would expect if the variables were independent)
If the observed counts differ greatly from the expected counts, the variables are likely not independent.
Example:
Suppose we want to test whether gender is independent of preference for a product.
A survey of 100 people gives:
| like product | dislike product | total | |
|---|---|---|---|
| Male | 30 | 20 | 50 |
| Female | 10 | 40 | 50 |
| Total | 40 | 60 | 100 |
Step 1: Hypotheses
: Gender and preference are independent.
: They are dependent
Step 2: Compute Expected Frequencies:
Using
Male like:
Male dislike:
Female like:
Female dislike:
Expected table:
| like | dislike | |
|---|---|---|
| Male | 20 | 30 |
| Female | 20 | 30 |
Step 3: Compute statistic
Step 4: Degrees of Freedom
Step 5: Critical Value
At
Step 6: Decision
Therefore we reject the null hypethesis.
Conclusion
There is significant evidence that gender and product preference are associated (not independent).
Explain the F-test statistic for comparing two variances.
The F-test is used in Statistical Inference to determine whether two populations have the same variance. It compares the variability of two independent samples. The test statistic follows the F-distribution, introduced by Ronald A. Fisher, which is the distribution of the ratio of two independent scaled chi-square random variables.
The F-test answers questions such as:
- Do two production machines produce items with the same variability?
- Are two measurement methods equally precise?
- Do two populations have equal variances?
This test is also the basis for analysis of variance (ANOVA).
Hypotheses:
For two populations:
where and are population variances.
Test Statistic
The F statistic is
where
- - sample variance of sample 1.
- - sample variance of sample 2.
Usually the larger variance is placed in the numerator so that .
Distribution
Under :
where
- and are sample sizes
- degrees of freedom:
Assumptions
The F-test requires:
- Independent samples
- Normally distributed populations
- Random sampling
Example:
Suppose two machines produce metal rods, and we want to check if their variability in length is the same.
Samples:
| Machine | Sample size | Sample variance |
|---|---|---|
| A | 10 | 25 |
| B | 12 | 10 |
Step 1: Hypotheses
Step 2: Test Statistic
Place the larger variance in the numerator:
Step 3: Degrees of Freedom
So
Step 4: Critical Value
At significance level (right tail):
Step 5: Decision
Therefore do not reject the null hypothesis.
Conclusion
There is no sufficient evidence that the two machines have different variances.
Explain Likelihood Ratio Test (LRT) for General Parametric Models.
The Likelihood Ratio Test (LRT) is a general method in Statistical Inference for testing hypotheses about parameters in parametric statistical models.
The main idea is to compare:
- the maximum likelihood under the null hypothesis
- the maximum likelihood without restrictions
If the unrestricted model explains the data much better, the null hypothesis is rejected.
Let
- be likelihood function of parameter
- - the full parameter space
- - parameter values allowed under
The likelihood ratio statistic is
Where:
- numerator = maximum likelihood assuming
- denominator = maximum likelihood in the full model
Thus
Small values of indicate evidence against .
Test Statistic
Usually we use
A fundamental result (Wilks’ theorem) states that, for large samples:
where is the difference in number of parameters between models.
Decision Rule
Reject if
Example:
Suppose we observe data from a normal distribution:
Assume variance is known and is equal 1.
We want to test
Sample data:
Step 1: Likelihood Function
For normal data with variance 1:
The maximum likelihood estimator is
Step 2: Maximum Likelihoods
Under the full model:
Under the null hypothesis:
Step 3: Compute Statistic
Step 4: Distribution
Number of restricted parameters:
So
Critical value at :
Step 5: Decision
Therefore reject
Conclusion
There is significant evidence that the mean is different from 0.
Explain Non-Parametric / Rank-Based Tests.
Non-parametric (rank-based) tests are hypothesis tests that do not assume a specific parametric distribution for the population (e.g., normal distribution). Instead of relying on the raw values, they typically use ranks of the data.
They are especially useful when:
The distribution is unknown or not normal
Sample sizes are small
The data are ordinal (ranked) rather than numerical
The data contain outliers that would distort parametric tests
Non-parametric tests are often considered distribution-free alternatives to parametric tests such as the Z-test, t-test, or ANOVA.
Instead of using the raw data values , we:
- Sort the observaions
- Replace values with ranks
Example:
| Value | Rank |
|---|---|
| 3 | 1 |
| 5 | 2 |
| 8 | 3 |
| 10 | 4 |
Statistical tests are then performed on ranks rather than values. This makes the tests robust to distributional assumptions.
Explain p-value method for Hypotheses testing.
The p-value method is a common procedure in Statistical Inference for deciding whether to reject or not reject a null hypothesis based on observed data. Instead of comparing the test statistic directly with a critical value, we compute the probability of observing a result at least as extreme as the one obtained, assuming the null hypothesis is true.
The -value is:
observing a test statistic as extreme or more extreme than the observed one is true .
Thus it measures how incompatible the data are with the null hypothesis.
- Small -value: strong evidence against .
- Large -value: data are consistent with .
Let be the significance level (common 0.05).
Then the decision rule:
- If - reject .
- If - do not reject .
Example: Z-Test
Suppose a company claims the average battery life is 50 hours.
Sample data:
- sample mean
- population standard deviation
- sample size .
Test:
Significance level:
Step 1: Compute Test Statistic
Step 2: Compute p-Value
For a two-sided test:
From the standard normal distribution:
So
Step 3: Decision
Therefore reject .
What are Union Intersection and Intersection Union tests?
In Statistical Inference, Union–Intersection (UI) and Intersection–Union (IU) tests are general frameworks used when hypotheses involve multiple parameters or multiple conditions. They describe how a global hypothesis test can be constructed from several simpler tests.
1. Union–Intersection Test (UIT)Idea:
The null hypothesis is an intersection of several conditions, while the alternative is their union.
Interpretation:
- : all conditions hold simultaniously.
- : at least one condition is violated.
Decision Rule
Reject if any of the individual tests rejects its corresponding
2. Intersection–Union Test (IUT)
Idea:
Here the hypotheses are reversed. The null hypothesis is a union, and the alternative is an intersection.
Interpretation:
- : at least one condition holds.
- : all conditions must hold simultaniously.
Decision Rule
Reject only if all individual tests reject.
Explain Analysis of Variance (ANOVA) method.
ANOVA (Analysis of Variance) is a statistical method used to test whether the means of several populations are equal. It extends the idea of the two-sample t-test to more than two groups. ANOVA tests whether differences among sample means are statistically significant or simply due to random variation. Typical question is if several groups have the same population mean. It can be interpreted as a Union–Intersection Test (UIT).
Example applications:
- Comparing effectiveness of different drugs
- Comparing teaching methods
- Comparing production processes
Hypotheses:
Suppose we have groups with means:
Hypotheses:
:
: at least one differs
ANOVA analyzes two sources of variability in the data:
- Between-group variability: variation between the group means
- Within-group variability: variation inside each group
If group means are truly equal, these two types of variation should be similar.
If the between-group variation is much larger, the means are likely different.
Let
- be the observation in group .
- - mean of group .
- - overall mean.
Toatl variability:
This splits into:
where
Between-group variation
Within group variation
We divide sums of squares by their degrees of freedom.
Between groups:
Within groups:
where
- k - number of groups
- N - total number of observations
The ANOVA statistic is represented by F-statistic:
Under the null hypothesis:
A large F value suggests the group means are different.
Explain Bayesian method for hypothesis testing.
In Bayesian hypothesis testing, hypotheses are treated as probabilistic models, and inference is based on updating beliefs using Bayes’ theorem. This approach belongs to Bayesian Statistics. Unlike classical testing, where hypotheses are rejected or not rejected, Bayesian methods evaluate how probable each hypothesis is after observing the data.
Suppose we have two competing hypotheses:
Bayesian analysis assigns prior probabilities to the hypotheses:
After observing data , we compute posterior probabilities:
using Bayes’ theorem:
where:
- likelihood under .
The central tool in Bayesian hypothesis testing is the Bayes factor.
It measures how much the data support one hypothesis over the other.
Bayesian testing often compares posterior odds:
Example: Suppose we test whether a coin is fair.
Hypothesises:
We flip the coin 10 times and observe 8 heads.
Likelihood under
Likelihood under For we assume a prior distribution for .
For example:
Then the likelihood is obtained by integrating over all possible :
Bayes Factor
Since
the data favor (the coin may not be fair).
Decision rule:
Instead of fixed rejection regions, Bayesian testing uses:
- Posterior probability comparison
or
- Bayes factor thresholds
Example rule:
Reject if:
Enlist and explain main methods of evaluation of hypothesis tests.
1. Type I Error Probability (Significance Level)
A Type I error occurs when we reject the null hypothesis even though it is true.
- is called significance level
- common values are between 0.01 and 0.05
A good test should control the probability of Type I error.
2. Type II Error Probability
A Type II error occurs when we fail to reject even though it is false.
A good test should minimize this probability.
3. Power of the Test
The power of a test is the probability of correctly rejecting the null hypothesis when it is false.
Thus
A test with higher power is better because it detects real effects more reliably.
4. Power Function
The power function describes the probability of rejecting for every possible parameter value.
Properties:
- Under :
- Under : should be as large as possible
5. Most Powerful Test
A test is most powerful if it has the largest power among all tests with the same significance level .
6. Uniformly Most Powerful Test (UMP)
A test is uniformly most powerful if it has the highest power for all parameter values in the alternative hypothesis.
7. Consistency of a Test
A test is consistent if its power approaches 1 as the sample size increases when the alternative hypothesis is true.
Thus with large samples, the test will almost surely detect the false null hypothesis.
What are the interval estimators in statistical inference?
Interval estimators (confidence intervals) provide a range of plausible values for an unknown parameter rather than a single estimate.
Several methods exist for constructing interval estimators.
- Pivot (Pivotal Quantity) Method.
- Test Inversion Method.
- Likelihood-Based Method.
- Asymptotic (Normal Approximation) Method.
- Bayesian Credible Intervals.
- Bootstrap Method.
Explain and give a simple example for Pivot (Pivotal Quantity) Method.
The Pivot Method is one of the classical approaches to constructing confidence intervals in Statistical Inference. It is based on a pivotal quantity, which is a function of the sample and the parameter whose probability distribution does not depend on the unknown parameter.
Definition of a Pivot
A pivotal quantity satisfies:
This allows us to use known distributions to find intervals for .
Steps to Construct an Interval Using a Pivot
- Identify a pivotal qunatity .
- Find its distribution, usually standard (Normal, t, , etc).
- Solve the probability statement for :
to get the confidence interval.
Example:
Suppose we have:
where is a known value.
We want a 95% confidence interval for .
Step 1: Identify pivot:
The natural pivot is the standardized sample mean:
- is standadrd normal.
- its distrubution does not depend on .
Step 2: Use Probability Statement
For 95% confidence:
where .
Step 3: Solve for
Multiply both sides by and solve:
This is the 95% confidence interval for .
Explain Test Inversion method for finding confidence intervals.
The Test Inversion Method is a classical approach in Statistical Inference for constructing confidence intervals by inverting a family of hypothesis tests. Instead of directly finding a formula for the interval, you identify all parameter values that would not be rejected by a suitable hypothesis test.
Idea:
- Consider a parameter .
- For each candidate value perform a hypothesis test:
- Collect all for which was not rejected.
This set of forms the confidence interval.
Steps:
- Choose a test statistic fro testing .
- Determine the rejection region based on the chosen significance level .
- Invert the test: find all such that does not fall in the rejection region.
- The resulting set of values is the confidence interval.
Explain Likelihood-Based Method for Interval Estimation.
The Likelihood-Based Method constructs confidence intervals using the likelihood function of the parameter. It is widely used in Statistical Inference and is closely related to maximum likelihood estimation (MLE) and likelihood ratio tests.
Parameter values that produce likelihoods close to the maximum likelihood are considered plausible values for the parameter.
To construct an interval, we compare the likelihood at with the maximum likelihood.
Likelihood ratio:
Values of for which this ratio is not too small are included in the confidence interval.
A common form for likelihood ratio confidence interval is
where
- is the log likelihood.
- is the MLE.
- is the chi-square critical value with 1 degree of freedom.
This set of values forms the confidence interval.
Explain Asymptotic (Normal Approximation) Method for Interval Estimation.
The Asymptotic Method constructs confidence intervals using the fact that many estimators become approximately normally distributed for large sample sizes. This method is widely used in Statistical Inference. The word asymptotic means that the result becomes accurate as the sample size becomes large.
Key Idea:
For many estimators :
More precisely:
This allows us to construct a confidence interval using the standard normal distribution.
General formula for the interval:
Using the standard normal quantile :
where
- is estimator
- - variance of the estimator
If the variance is unknown, we replace it with an estimate.
Explain Bootstrap Method for Interval Estimation.
The Bootstrap Method is a computational technique used to estimate confidence intervals when the sampling distribution of an estimator is difficult to derive analytically. It is widely used in Statistical Inference. The idea is to approximate the sampling distribution of an estimator by resampling from the observed data.
Basic Idea:
Normally, to understand the distribution of an estimator , we would repeatedly sample from the population. In practice, we only have one sample. Bootstrap solves this by treating the observed sample as an approximation of the population and repeatedly sampling from it. Thus we simulate many new datasets from the original data.
Bootstrap procedure:
Suppose we have a sample:
and an estimator .
- Draw a bootstrap sample of size from the original data with replacement.
- Compute the estimator for this sample
- Repeat this process many times (e.g., 1000 or 10000 samples).
This produces a set of bootstrap estimates:
which approximate the sampling distribution of .
Constructing a confidence interval:
A simple method is the percentile bootstrap interval. Sort the bootstrap estimates and take empirical quantiles:
For a 95% confidence interval:
- lower bound 2.5th percentile (position of the value in the order statistic is )
- upper bound 97.5th percentile (position of the value in the order statistic is ).
Explain Bayesian Credible Intervals estimation.
In Bayesian Statistics, an interval estimator is called a credible interval. It represents a range of parameter values that contains a specified posterior probability given the observed data. Unlike classical confidence intervals, credible intervals are derived from the posterior distribution of the parameter.
Definition
Let be be an unknown parameter and let be the posterior distribution given data . A credible interval satisfies
Given the observed data, the probability that the parameter lies in the interval is .
How it is constructed
1. Choose a prior distribution.
Specify a prior for the parameter:
Step 2: Compute the Posterior Distribution.
Using Bayes’ theorem:
where
- is likelihood
- - prior
Step 3: Find an Interval Containing Posterior Probability.
Select values and such that
Types of credible intervals
Equal-Tailed Credible Interval
The probability outside the interval is split equally:Thus:
This is the most common type.
Highest Posterior Density (HPD) Interval
The HPD interval contains the values of with the highest posterior density.Properties:
- Contains probability
- Shortest possible credible interval
Condition:
for some constant .
What are the methods of evaluating interval estimators?
In Statistical Inference, interval estimators (confidence intervals) are evaluated by how well they capture the true parameter and how precise they are. The main evaluation criteria are the following.
1. Coverage Probability (Confidence Level)
The coverage probability is the probability that the interval estimator contains the true parameter value.
If the interval estimator is , then the covarage probability is
A good estimator should satisfy:
for all possible values of .
This is the most important property of a confidence interval.
2. Expected Length of the Interval
The length of the interval is
Since the interval depends on the sample, we consider its expected length:
A shorter interval is preferred because it gives a more precise estimate of the parameter.
Thus we want:
- high coverage probability
- small expected length
However, there is a trade-off: increasing coverage usually increases the interval length.
3. Uniform Coverage
A desirable property is that the coverage probability holds for every value of the parameter:
for all .
If coverage varies with , the interval may be unreliable for some parameter values.
4. Unbiasedness of the Interval
An interval estimator is sometimes evaluated by whether it is balanced around the parameter.
Formally, we may require
This means the probability that the interval misses the parameter on the left and right sides is equal.
This leads to equal-tailed intervals.
5. Optimal Intervals (Shortest Length)
Among all intervals with the same coverage probability, we often prefer the one with minimal expected length.
Example:
- Shortest confidence interval
- Highest posterior density (HPD) interval in Bayesian inference
These intervals provide the most precise estimation.
Interview questions for Databases.
Sources:
www.softwaretestinghelp.com/database-interview-questions/
www.mindmajix.com/nosql-interview-questions
www.ibm.com/docs/en/ida/9.1.1?topic=entities-primary-foreign-keys
How is a Database defined?
Database is an organized collection of related data where the data is stored and organized to serve some specific purpose.
Define DBMS.
DBMS stands for Database Management System. It is a collection of application programs which allow the user to organize, restore and retrieve information about data as effectively as possible. Some of the popular DBMS’s are MySql, Oracle, PostgreSql, SqLite, etc.
Define RDBMS.
Relational Database Management System (RDBMS) is based on a relational model of data that is stored in databases in separate tables and they are related to the use of a common column. Data can be accessed easily from the relational database using Structured Query Language (SQL).
Enlist the advantages of DBMS.
The advantages of DBMS includes:
- Data is stored in a structured way and hence redundancy is controlled.
- Validates the data entered and provide restrictions on unauthorized access to the database.
- Provides backup and recovery of the data when required.
- It provides multiple user interfaces.
What is the Database Transaction?
Sequence of operation performed which changes the consistent state of the database to another is known as the database transaction. After the completion of the transaction, either the successful completion is reflected in the system or the transaction fails and no change is reflected.
Enlist four fundamental Properties of Transactions in RDBMS.
Four crucial properties define relational database transactions: atomicity, consistency, isolation, and durability—typically referred to as ACID.
- Atomicity defines all the elements that make up a complete database transaction.
- Consistency defines the rules for maintaining data points in a correct state after a transaction.
- Isolation keeps the effect of a transaction invisible to others until it is committed, to avoid confusion.
- Durability ensures that data changes become permanent once the transaction is committed.
Explain the terms ‘Record’, ‘Field’ and ‘Table’ in terms of database.
Record: Record is a collection of values or fields of a specific entity. For Example, An employee, Salary account, etc.
Field: A field refers to an area within a record that is reserved for specific data. For Example, Employee ID.
Table: Table is the collection of records of specific types. For Example, the Employee table is a collection of records related to all the employees.
What do you understand by Data Redundancy?
Duplication of data in the database is known as data redundancy. As a result of data redundancy, duplicated data is present at multiple locations, hence it leads to wastage of the storage space and the integrity of the database is destroyed.
What is a Primary Key in a Relational Database?
A Primary Key is a column or a set of columns in a table whose values uniquely identify a row in the table. A relational database is designed to enforce the uniqueness of primary keys by allowing only one row with a given primary key value in a table.
What is a Foreign Key in a Relational Database?
A Foreign Key is a column or a set of columns in a table whose values correspond to the values of the primary key in another table. In order to add a row with a given foreign key value, there must exist a row in the related table with the same primary key value.
What are Non-key Attributes?
Non-key attributes are attributes that are not part of any key. Generally, most attributes are simply descriptive, and fall into this category. Consider an Employee entity type that has attributes for first name, last name, birth date; these attributes would serve to describe an employee but would not serve to uniquely identify employees.
Categorize Data Modification Anomalies in a Database.
- Insertion Anomaly: Insertion Anomaly refers to when one cannot insert a new tuple into a relationship due to lack of data.
- Deletion Anomaly: The delete anomaly refers to the situation where the deletion of data results in the unintended loss of some other important data.
- Updatation Anomaly: The update anomaly is when an update of a single data value requires multiple rows of data to be updated.
What are the various types of relationships in Database? Define them.
There are 3 types of relationships in Database:
- One-to-one: One table has a relationship with another table having the similar kind of column. Each primary key relates to only one or no record in the related table.
- One-to-many: One table has a relationship with another table that has primary and foreign key relations. The primary key table contains only one record that relates to none, one or many records in the related table.
- Many-to-many: Each record in both the tables can relate to many numbers of records in another table.
Explain Normalization and De-Normalization.
Normalization is the process of removing redundant data from the database by splitting the table in a well-defined manner in order to maintain data integrity. This process saves much of the storage space. It is also used to eliminate undesirable characteristics like Insertion, Update, and Deletion Anomalies.
De-normalization is the process of adding up redundant data on the table in order to speed up the complex queries and thus achieve better performance.
What are the different types of Normalization?
Different types of Normalization are:
- First Normal Form (1NF): A relation is said to be in 1NF only when all the entities of the table contain unique or atomic values. It meens all rows must be unique, each cell must contain only single value (not a list) and each value should be non-divisible (can't be split down further).
- Second Normal Form (2NF): A relation is said to be in 2NF only if it is in 1NF and all the non-key attribute of the table is fully dependent on the primary key. For example we have a table with columns composed of Student ID, Course ID and Course Fee. Course Fee does not depend fully on the primary key represented by Student ID. In order to achieve 2NF on splits the table in one that contains Student ID and Course ID and another that contains Course ID and Course Fee.
- Third Normal Form (3NF): A relation is said to be in 3NF only if it is in 2NF and every non-key attribute of the table is not transitively dependent on the primary key. For example if we have a table containing Tournament Name, Year, Winner's Name and Winner's Date of Birth. Winners date of birth can be defined by winner's name and not by the primary key represented by tournament name and year, so the table must be split.
What is BCNF?
BCNF is the Boyce Code Normal form. It is the higher version of 3Nf which does not have any multiple overlapping candidate keys. For example if we have a table with Student ID, Corse ID and Professor ID, where the same course could be held by different professors, we have to split the table into table eith Student ID and professor ID and the table with professor ID and Course ID.
What is SQL?
Structured Query language, SQL is an ANSI (American National Standard Institute) standard programming language that is designed specifically for storing and managing the data in the relational database management system (RDBMS) using all kinds of data operations.
How many SQL statements are used? Define them.
SQL statements are basically divided into three categories, DDL, DML, and DCL.
They can be defined as:
- Data Definition Language (DDL) commands are used to define the structure that holds the data. These commands are auto-committed i.e. changes done by the DDL commands on the database are saved permanently.
- Data Manipulation Language (DML) commands are used to manipulate the data of the database. These commands are not auto-committed and can be rolled back.
- Data Control Language (DCL) commands are used to control the visibility of the data in the database like revoke access permission for using data in the database.
Enlist some commands of DDL, DML and DCL.
Data Definition Language (DDL) commands:
CREATE to create a new table or database.
ALTER for alteration.
TRUNCATE to delete data from the table.
DROP to drop a table.
RENAME to rename a table.Data Manipulation Language (DML) commands:
INSERT to insert a new row.
UPDATE to update an existing row.
DELETE to delete a row.
MERGE for merging two rows or two tables.Data Control Language (DCL) commands:
COMMIT to permanently save.
ROLLBACK to undo the change.
SAVEPOINT to save temporarily.
What is Quaery Processor in DBMS?
The Query Processor receives the queries (requests) from the user and interprets them in the form of instructions. It has four components: DML Compiler, DDL Interpreter, Query Optimizer and Embedded DML Pre-compiler.
Define DML Compiler.
It converts the DML (Data Manipulation Language) Instructions into Machine Language (low-level language).
What is DDL interpreter?
It interprets the DDL (Data Definition Language) Instructions and stores the record in a data dictionary (in a table containing meta-data).
What is Query Optimizer?
It executes the DML Instructions and picks the lowest cost evaluation plan out of all the alternatives present.
What is Embedded DML Pre-compiler?
It translates the DML statements embedded in Application Programs into procedural function calls.
Enlist the advantages of SQL.
- Simple SQL queries can be used to retrieve a large amount of data from the database very quickly and efficiently.
- SQL is easy to learn and almost every DBMS supports SQL.
- It is easier to manage the database using SQL as no large amount of coding is required.
What is a Relational Database Schema?
A database schema refers to the logical and visual configuration of the entire relational database. The database objects are often grouped and displayed as tables, functions, and relations. A schema describes the organization and storage of data in a database and defines the relationship between various tables.
What is a Physical Level in a Relational Database.
The concept of Physical Level in a database refers to the lowest level of organization and representation of data in a database management system. At the physical level, data is represented in the form of bits, bytes, and blocks of data stored on a storage device (such as a hard drive or solid-state drive).
What is a Conceptual (Logical) Level in a Relational Database.
The conceptual level is a way of describing what data is stored within the whole database and how the data is inter-related. The conceptual level does not specify how the data is physically stored.
What is a View Level in a Relational Database?
Views are virtual tables. They are only a structure, and contain no data. Their purpose is to allow a user to see a subset of the actual data. A view can consist of a subset of one table. A View can be considered as a template query.
What are the advantages and disadvantages of views in the database?
Advantages of Views:
- As there is no physical location where the data in the view is stored, it generates output without wasting resources.
- Data access is restricted as it does not allow commands like insertion, updation, and deletion.
Disadvantages of Views:
- The view becomes irrelevant if we drop a table related to that view.
- Much memory space is occupied when the view is created for large tables.
What do you understand by Data Independence? What are its two types?
Data Independence refers to the ability to modify the schema definition in one level in such a way that it does not affect the schema definition in the next higher level.
The 2 types of Data Independence are:
- Physical Data Independence: It modifies the schema at the physical level without affecting the schema at the conceptual level.
- Logical Data Independence: It modifies the schema at the conceptual level without affecting or causing changes in the schema at the view level.
What do you understand by Functional dependency?
A relation is said to be in functional dependency when one attribute uniquely defines another attribute. For Example, R is a Relation, X and Y are two attributes. T1 and T2 are two tuples. Then,
T1[X]=T2[X] and T1[Y]=T2[Y]
Means, the value of component X uniquely define the value of component Y. Also, X->Y means Y is functionally dependent on X.
What is a Fully Functional Dependancy?
To fulfill the criteria of fully functional dependency, the relation must meet the requirement of functional dependency. A functional dependency ‘A’ and ‘B’ are said to be fully functional dependent when removal of any attribute say ‘X’ from ‘A’ means the dependency does not hold anymore.
What do you understand by the E-R model?
E-R model is an Entity-Relationship model which defines the Conceptual View of the database. The E-R model basically shows the real-world entities and their association/relations. Entities here represent the set of attributes in the database.
Define Entity, Entity type, and Entity set.
Entity can be anything, be it a place, class or object which has an independent existence in the real world.
Entity Type represents a set of entities that have similar attributes.
Entity Set in the database represents a collection of entities having a particular entity type.
What is a Weak Entity?
In a relational database, a weak entity is an entity that cannot be uniquely identified by its attributes alone; therefore, it must use a foreign key in conjunction with its attributes to create a primary key. The foreign key is typically a primary key of an entity it is related to.
Explain the terms ‘Attribute’ and ‘Relations’.
Attribute is described as the properties or characteristics of an entity. For Example, Employee ID, Employee Name, Age, etc., can be attributes of the entity Employee.
Relation is a two-dimensional table containing a number of rows and columns where every row represents a record of the relation. Here, rows are also known as ‘Tuples’ and columns are known as ‘Attributes’.
What are VDL and SDL?
VDL is View Definition Language which represents user views and their mapping to the conceptual schema.
SDL is Storage Definition Language which specifies the mapping between two schemas.
Define Cursor and its types.
Cursor is a temporary work area that stores the data, as well as the result set, occurred after manipulation of data retrieved. A cursor can hold only one row at a time.
The 2 types of Cursor are:
- Implicit cursors are declared automatically when DML statements like INSERT, UPDATE, DELETE is executed.
- Explicit cursors have to be declared when SELECT statements that are returning more than one row are executed.
Define Database Lock and its types.
Database lock basically signifies the transaction about the current status of the data item i.e. whether that data is being used by other transactions or not at the present point of time.
There are two types of Database lock: Shared Lock and Exclusive Lock.
Shared Lock exist when two transactions are granted read access. One transaction gets the shared lock on data and when the second transaction requests the same data it is also given a shared lock. Both transactions are in a read-only mode, updating the data is not allowed until the shared lock is released.
An Exclusive Lock means that no other users can update or delete the item until the database server removes the lock.
What is Data Warehousing?
Data Warehousing integrates data and information collected from various sources into one comprehensive database. For example, a data warehouse might combine customer information from an organization's point-of-sale systems, its mailing lists, website, and comment cards.
What do you understand by Join?
Join is the process of deriving the relationship between different tables by combining columns from one or more tables having common values in each. When a table joins with itself, it is known as Self Join.
What do you understand by Index Hunting?
Index hunting is the process of boosting the collection of indexes which helps in improving the query performance as well as the speed of the database (in analogy with direct access by index in a lookup table).
How to improve query performance using Index hunting?
Index hunting help in improving query performance by:
- Using a query optimizer to coordinate queries with the workload.
- Observing the performance and effect of index and query distribution.
Differentiate between ‘Cluster’ and ‘Non-cluster’ index.
Clustered Index alters the table and re-order the way in which the records are stored in the table. Data retrieval is made faster by using the clustered index. SQL Server clustered index creates a physical sorted data structure of the table rows according to the defined index key. This sorted data structure is called a B-tree (balanced tree). B-tree structure enables us to find the queried rows faster to using the sorted key value(s).
A Non-clustered Index does alter the records that are stored in the table but creates a completely different object within the table.
What do you understand by Fragmentation?
Fragmentation is a feature that controls the logical data units, also known as fragments that are stored at different sites of a distributed database system.
Define Join types.
Given below are the types of Join, which are explained with respect to the tables as an example.
employee Table
| EmpID | EmpName |
| 1000 | Kolya |
| 1001 | Tolya |
| 1002 | Sasha |
| 1003 | Alexey |
employee_info Table
| EmpID | Adress |
| 1000 | Moscow |
| 1001 | Spb |
| 1002 | Nijniy |
| 1003 | Novosib |
- Inner JOIN: Inner JOIN is also known as a simple JOIN. This SQL query returns results from both the tables having a common value in rows. SQLQuery:
SELECT * from employee, employee_info WHERE employee.EmpID = employee_info.EmpID
Result:
| EmpID | EmpName | EmpID | Adress |
| 1000 | Kolya | 1000 | Moscow |
| 1001 | Tolya | 1001 | Spb |
| 1002 | Sasha | 1002 | Nijniy |
| 1003 | Alexey | 1003 | Novosib |
- Natural JOIN This is a type of Inner JOIN that returns results from both the tables having the same data values in the columns of both the tables to be joined. SQLQuery:
SELECT * from employee NATURAL JOIN employee_info
Result:
| EmpID | EmpName | Adress |
| 1000 | Kolya | Moscow |
| 1001 | Tolya | Spb |
| 1002 | Sasha | Nijniy |
| 1003 | Alexey | Novosib |
- Cross JOIN: Cross JOIN returns the result as all the records where each row from the first table is combined with each row of the second table.
SQLQuery:
SELECT * from employee CROSS JOIN employee_info;
- Right JOIN: Right JOIN is also known as Right Outer JOIN. This returns all the rows as a result from the right table even if the JOIN condition does not match any records in the left table.
employee Table
| EmpID | EmpName |
| 1000 | Kolya |
| 1001 | Tolya |
| 1002 | Sasha |
| 1003 | Alexey |
| 1004 | Masha |
| 1005 | Dasha |
employee_info Table
| EmpID | Adress |
| 1000 | Moscow |
| 1001 | Spb |
| 1002 | Nijniy |
| 1003 | Novosib |
| 1006 | Tomsk |
| 1007 | Almaty |
SQLQuery:
SELECT * from employee RIGHT OUTER JOIN employee_info on (employee.EmpID = employee_info.EmpID);
Result:
| EmpID | EmpName | EmpID | Adress |
| 1000 | Kolya | 1000 | Moscow |
| 1001 | Tolya | 1001 | Spb |
| 1002 | Sasha | 1002 | Nijniy |
| 1003 | Alexey | 1003 | Novosib |
| Null | Null | 1006 | Tomsk |
| Null | Null | 1007 | Almaty |
- Left JOIN: Left JOIN is also known as Left Outer JOIN. This returns all the rows as a result of the left table even if the JOIN condition does not match any records in the right table. This is exactly the opposite of Right JOIN.
SQLQuery:
SELECT * from employee LEFT OUTER JOIN employee_info on (employee.EmpID = employee_info.EmpID);
Result:
| EmpID | EmpName | EmpID | Adress |
| 1000 | Kolya | 1000 | Moscow |
| 1001 | Tolya | 1001 | Spb |
| 1002 | Sasha | 1002 | Nijniy |
| 1003 | Alexey | 1003 | Novosib |
| 1004 | Masha | Null | Null |
| 1005 | Dasha | Null | Null |
- Outer/Full JOIN: Full JOIN return results in combining the result of both the Left JOIN and Right JOIN.
SQLQuery:
SELECT * from employee FULL OUTER JOIN employee_info on (employee.EmpID = employee_info.EmpID);
Result:
| EmpID | EmpName | EmpID | Adress |
| 1000 | Kolya | 1000 | Moscow |
| 1001 | Tolya | 1001 | Spb |
| 1002 | Sasha | 1002 | Nijniy |
| 1003 | Alexey | 1003 | Novosib |
| 1004 | Masha | Null | Null |
| 1005 | Dasha | Null | Null |
| Null | Null | 1006 | Tomsk |
| Null | Null | 1007 | Almaty |
What do you understand by ‘Atomicity’ and ‘Aggregation’?
Atomicity is the condition where either all the actions of the transaction are performed or none. This means, when there is an incomplete transaction, the database management system itself will undo the effects done by the incomplete transaction.
Aggregation is the concept of expressing the relationship with the collection of entities and their relationships.
Define Phantom Deadlock.
Phantom deadlock detection is the condition where the deadlock does not actually exist but due to a delay in propagating local information, deadlock detection algorithms identify the deadlocks.
Define Checkpoint.
Checkpoint declares a point before which all the logs are stored permanently in the storage disk and the database is in consistent state. In the case of crashes, the amount of work and time is saved as the system can restart from the checkpoint.
What is Database Partitioning?
Database partitioning is the process of partitioning tables, indexes into smaller pieces in order to manage and access the data at a finer level. This process of partitioning reduces the cost of storing a large amount of data as well as enhances the performance and manageability.
Explain the importance of Database Partitioning.
- Improves query performance and manageability.
- Simplifies common administration tasks.
- Acts as a key tool for building systems with extremely high availability requirements.
- Allows accessing a large part of a single partition.
Explain the Data Dictionary.
Data Dictionary is a set of information describing the content and structure of the tables and database objects. The job of the information stored in the data dictionary is to control, manipulate and access the relationship between database elements.
Explain the Primary Key and Composite Key.
Primary Key is that column of the table whose every row data is uniquely identified. Every row in the table must have a primary key and no two rows can have the same primary key. Primary key value can never be null nor can it be modified or updated.
Composite Key is a form of the candidate key where a set of columns will uniquely identify every row in the table.
What do you understand by the Unique key?
A Unique key is the same as the primary key whose every row data is uniquely identified with a difference of null value i.e. Unique key allows one value as a NULL value.
What do you understand by Database Triggers?
A set of commands that automatically get executed when an event like Before Insert, After Insert, On Update, On Delete of row occurs in a table is called a Database Trigger.
Define Stored Procedures.
A Stored procedure is a collection of pre-compiled SQL Queries, which when executed denotes a program taking input, process and gives the output.
What do you understand by B-Trees?
B-Tree represents the data structure in the form of a tree for external memory that reads and writes large blocks of data. It is commonly used in databases and file systems where all the insertions, deletions, sorting, etc., are done in logarithmic time.
Name the different Data Models that are available for database systems.
- Relational model
- Network model
- Hierarchical model
Differentiate between ‘DELETE’, ‘TRUNCATE’ and ‘DROP’ commands.
After the execution of DELETE operation, COMMIT and ROLLBACK statements can be performed to retrieve the lost data.
After the execution of TRUNCATE operation, COMMIT, and ROLLBACK statements cannot be performed to retrieve the lost data.
DROP command is used to drop the table or key like the primary key/foreign key.
Based on the given table, solve the following queries.
employee Table
| EmpID | EmpName | Age | Adress |
| 1000 | Kolya | 26 | Moscow |
| 1001 | Tolya | 30 | Spb |
| 1002 | Sasha | 22 | Nijniy |
| 1003 | Alexey | 50 | Novosib |
| 1004 | Masha | 28 | Kaliningrad |
a) Write the SELECT command to display the details of the employee with empid as 1004. SQLQuery:
SELECT EmpId, EmpName, Age, Adress from Employee WHERE empId = 1004;
Result:
| EmpID | EmpName | Age | Adress |
| 1004 | Masha | 28 | Kaliningrad |
b) Write the SELECT command to display all the records of table Employees.
SQLQuery:
SELECT * from Employee;
c) Write the SELECT command to display all the records of the employee whose name starts with the character ‘T’.
SQLQuery:
SELECT * from Employee WHERE EmpName LIKE ‘T%’;
d) Write a SELECT command to display id, age and name of the employees with their age in both ascending and descending order.
SQLQuery:
SELECT EmpId, EmpName, Age from Employee  ORDER BY Age;
SQLQuery:
SELECT EmpId, EmpName, Age from Employee  ORDER BY Age Desc;
What do you understand by NoSQL?
Nowadays, developers are dealing with a large volume of data which is called Big Data. So naturally, big complexity and big issues will be there. Once most of the systems are getting online, so data load increases. NoSQL helps to manage unstructured, messy, and complicated data. This is not a traditional database or relational database management.
How many types of NoSQL Databases are there?
- Graph Database - stores nodes and relationships instead of tables or documents. Data is stored just like you might sketch ideas on a whiteboard. Your data is stored without restricting it to a pre-defined model, allowing a very flexible way of thinking about and using it. For example Neo4j is a Graph Database.
- Key Value Calculation - stores data as a collection of key-value pairs in which a key serves as a unique identifier. Both keys and values can be anything, ranging from simple objects to complex compound objects. Key-value databases (or key-value stores) are highly partitionable and allow horizontal scaling at a level that other types of databases cannot achieve. Examples are DynamoDB, Cassandra, Redis, etc.
- Document Oriented - a special type of Key-Value Store where keys can only be Strings. Moreover, the document is encoded using standards like JSON or related languages like XML (Semi-Structured Data). You can also store PDFs, image files, or text documents directly as values. Examples are CouchDB, MongoDB, etc.
- Column View Presentation - represents data in columnar form reducing the number of I/O operations on hardrives. Used in warehouses for big data analytics.
Write down the difference between vertical and horizontal databases.
Horizontal Scaling means that you scale by adding more machines into your pool of resources whereas Vertical Scaling means that you scale by adding more power (CPU, RAM) to an existing machine.
An easy way to remember this is to think of a machine on a server rack, we add more machines across the horizontal direction and add more resources to a machine in the vertical direction.
In the database world, horizontal-scaling is often based on the partitioning of the data i.e. each node contains only part of the data, in vertical-scaling the data resides on a single node and scaling is done through multi-core i.e. spreading the load between the CPU and RAM resources of that machine.
When should one use NoSQL in place of the normal database?
If you are looking for key-value stores with massive high-speed performances, you can use NoSQL. Because in the relational databases, we use ACID transactions. Once we use this kind of transaction, the schema-based process will slow down the database performance.
Suggestive possible situations to use NoSQL are:
- If you use multiple JOIN queries.
- If the client wants high traffic site.
- If you are using denormalized data.
What do you know about polyglot persistence in NoSQL?
Polyglot persistence is a hybrid approach enabling usage of multiple databases in a single application/software. A Software that is capable of using more than one type of data storage is referred to as Polyglot-persistent software.
Clarify the Key-Value Approach in a NoSQL Database.
Key-Value Approach implies storing data in a Hash Table. Searching data in a hash table is of constant time complexity, which makes it very fast.
Explain the CAP theorem in NoSQL.
CAP theorem or Eric Brewers theorem states that we can only achieve at most two out of three guarantees for a database: Consistency, Availability, and Partition Tolerance.
What is Sharding an a NoSQL Database?
Sharding is a method of storing data records across many server instances. This is done through storage area networks to make hardware perform like a single server. The NoSQL framework is natively designed to support automatic distribution of the data across multiple servers including the query load.
What is Big SQL?
IBM Db2 Big SQL is a high performance massively parallel processing (MPP) SQL engine for Hadoop (software framework for distributed storage and processing of big data) that makes querying enterprise data from across the organization an easy and secure experience. A Db2 Big SQL query can quickly access a variety of data sources including HDFS (Hadoop Distributed File Scheme), GPFS (General Parallel File System), RDBMS, NoSQL databases, object stores, and WebHDFS by using a single database connection or single query for best-in-class analytic capabilities.
How does Impedance Mismatch Happening in a Database?
A Programming Impedance Mismatch occurs when data needs to be transformed into a different architectural paradigm. The most prominent example involves object-oriented codebases and relational databases. An impedance mismatch arises when data is fetched from or inserted into a database. The properties of objects or classes within the codebase need to be mapped to their corresponding database table fields.
What is an Aggregate-Oriented Database
Typical Aggregate-Oriented NoSQL databases will store an aggregation in the form of strings or entire documents. That is usually in plain text, often in a specific format or notation, such as JSON or XML. In the case of document NoSQL databases, the “value” portion of the entry can get much larger.
What is eventual consistency in the context of NoSQL?
Eventual consistency is a data modeling concept that ensures that updates made to distributed NoSQL databases will eventually be reflected across all nodes. This ensures that identical database queries will return the same results after some period of time.
What are the BASE Properties in NoSQL?
BASE Properties aim to handle large volumes of data and enable scalability and flexibility in distributed systems. Here is a breakdown of what each property means:
- Basically Available: BASE systems prioritize availability over strong consistency. This means that even in the face of failures or concurrent updates, the system remains operational and accessible to users.
- Soft State: BASE systems allow for temporary inconsistency or partial updates. The state of the system can be transiently inconsistent during concurrent updates, but the system is eventually brought back to a consistent state.
- Eventual Consistency: BASE systems guarantee that updates will eventually propagate and reach a consistent state across all replicas or nodes. However, immediate consistency is not a requirement, and there may be a delay in achieving consistency.
Can Normalization be used in a NoSQL Database?
Yes, normalization can be used by a NoSQL database. One of the famous NoSQL named Cassandra (key-value database) is based on normalization to finding stored data. It creates a series of tables related to the different fields.
Interview questions for Python.
Sources:
www.interviewbit.com/python-interview-questions/
www.geeksforgeeks.org/python-interview-questions/
What is Python? What are the benfits of using it?
Python is a high-level, interpreted, dynamically typed, general-purpose programming language. It can be used to build almost any type of application with the right tools/libraries. Python supports objects, modules, threads, exception-handling, and automatic memory management which help in modelling real-world problems and building applications to solve these problems.
Benefits of using Python:
- Python is a general-purpose programming language that has a simple, easy-to-learn syntax that emphasizes readability and therefore reduces the cost of program maintenance. Moreover, the language is capable of scripting, is completely open-source, and supports third-party packages encouraging modularity and code reuse.
- Its high-level data structures, combined with dynamic typing and dynamic binding, attract a huge community of developers for Rapid Application Development and deployment.
Explain Interpreted Programming Language.
An interpreted language executes its statements line by line. Languages such as Python, Javascript, R, PHP, and Ruby are prime examples of Interpreted languages. Programs written in an interpreted language runs directly from the source code, with no intermediary compilation step.
What is a dynamically typed language?
Typing refers to type-checking in programming languages. In a strongly-typed language, such as Python, "1" + 2 will result in a type error since these languages don't allow for "type-coercion" (implicit conversion of data types). On the other hand, a weakly-typed language, such as Javascript, will simply output "12" as a result.
Type-checking can be done at two stages:
- Static - Data Types are checked before execution.
- Dynamic - Data Types are checked during execution.
Python is an interpreted language, executes each statement line by line and thus type-checking is done on the fly, during execution. Hence, Python is a Dynamically Typed Language.
What is PEP 8 and why is it important?
PEP stands for Python Enhancement Proposal. A PEP is an official design document providing information to the Python community, or describing a new feature for Python or its processes. PEP 8 is especially important since it documents the style guidelines for Python Code. Apparently contributing to the Python open-source community requires you to follow these style guidelines sincerely and strictly.
What is Scope in Python?
Every object in Python functions within a scope. A scope is a block of code where an object in Python remains relevant. Namespaces uniquely identify all the objects inside a program. However, these namespaces also have a scope defined for them where you could use their objects without any prefix. A few examples of scope created during code execution in Python are as follows:
- A Local Scope refers to the local objects available in the current function.
- A Global Scope refers to the objects available throughout the code execution since their inception.
- A Module-level Scope refers to the global objects of the current module accessible in the program.
- An Outermost Scope refers to all the built-in names callable in the program. The objects in this scope are searched last to find the name referenced.
What is the difference between Mutable and Immutable Data Types in Pyhon?
Mutable data types can be edited i.e., they can change at runtime. Eg – List, Dictionary, etc. Immutable data types can not be edited i.e., they can not change at runtime. Eg – String, Tuple, Byte and all single value built-in types.
What are lists and tuples? What is the key difference between the two?
Lists and Tuples are both sequence data types that can store a collection of objects in Python. The objects stored in both sequences can have different data types. Lists are represented with square brackets ['sara', 6, 0.19], while tuples are represented with parantheses ('ansh', 5, 0.97). The key difference between the two is that while lists are mutable, tuples on the other hand are immutable objects. This means that lists can be modified, appended or sliced on the go but tuples remain constant and cannot be modified in any manner.
What are the common built-in data types in Python?
There are several built-in data types in Python. Although, Python doesn't require data types to be defined explicitly during variable declarations type errors are likely to occur if the knowledge of data types and their compatibility with each other are neglected. Python provides type() and isinstance() functions to check the type of these variables. These data types can be grouped into the following categories:
- None Type: represents the null values in Python. Boolean equality operation can be performed using these NoneType objects.
- Numeric Types: there are three distinct numeric types - integers, floating-point numbers, and complex numbers. Additionally, booleans are a sub-type of integers.
- Sequence Types: there are four kinds of sequence data types: list (matable), tuple (immutable), range (immutable) and str(immutable).
- Mapping Types: dict (dictionary) is mutable data type that stores key-value pairs. Implemented as a Hash Map.
- Set Types: Currently, Python has two built-in types - set and frozenset. set type is mutable and supports methods like add() and remove(). frozenset type is immutable and can't be modified after creation.
- Modules: is an additional built-in type supported by the Python Interpreter. It supports one special operation, i.e., attribute access:
mymod.myobj, wheremymodis a module andmyobjreferences a name defined in m's symbol table. The module's symbol table resides in a very special attribute of the module dict, but direct assignment to this module is neither possible nor recommended. - Callable Types: Callable types are the types to which function call can be applied. They can be user-defined functions, instance methods, generator functions and some other built-in functions, methods and classes.
What is pass in Python?
The pass keyword represents a null operation in Python. It is generally used for the purpose of filling up empty blocks of code which may execute during runtime but has yet to be written.
How are arguments passed by value or by reference in Python?
Everything in Python is an object and all variables hold references to the objects. The reference values are according to the functions; as a result, you cannot change the value of the references. However, you can change the objects if it is mutable.
What is List Comprehension? Give an Example.
List comprehension is a syntax construction to ease the creation of a list based on existing iterable.
For Example:
my_list = [i for i in range(1, 10)]
What is a lambda function?
A lambda function is an anonymous function. This function can have any number of parameters but, can have just one statement.
For Example:
a = lambda x, y : x*y
print(a(7, 19))
What is the difference between / and // in Python?
/ represents precise division (result is a floating point number) whereas // represents floor division (result is an integer).
For Example:
5//2 = 2
5/2 = 2.5
How is Exceptional handling done in Python?
There are 3 main keywords i.e. try, except, and finally which are used to catch exceptions and handle the recovering mechanism accordingly. try is the block of a code that is monitored for errors. Except block gets executed when an error occurs.
The beauty of the final block is to execute the code after trying for an error. This block gets executed irrespective of whether an error occurred or not. final block is used to do the required cleanup activities of objects/variables.
What is swapcase function in Python?
It is a string’s function that converts all uppercase characters into lowercase and vice versa. It is used to alter the existing case of the string. This method creates a copy of the string which contains all the characters in the swap case.
For Example:
string = "PythonRules"
string.swapcase() ---> "pYTHONrULES"
Can we pass a function as an argument in Python?
Yes, Several arguments can be passed to a function, including objects, variables (of the same or distinct data types), and functions. Functions can be passed as parameters to other functions because they are objects. Higher-order functions are functions that can take other functions as arguments.
What are *args and *kwargs?
To pass a variable number of arguments to a function in Python, use the special syntax *args and **kwargs in the function specification. It is used to pass a variable-length, keyword-free argument list. By using the *, the variable we associate with the * becomes iterable, allowing you to do operations on it such as iterating over it and using higher-order operations like map and filter.
Is Indentation Required in Python?
Yes, indentation is required in Python. A Python interpreter can be informed that a group of statements belongs to a specific block of code by using Python indentation. Indentations make the code easy to read for developers in all programming languages but in Python, it is very important to indent the code in a specific order.
What is docstring in Python?
Python documentation strings (or docstrings) provide a convenient way of associating documentation with Python modules, functions, classes, and methods.
- Declaring Docstrings: The docstrings are declared using ”’triple single quotes”’ or “””triple double quotes””” just below the class, method, or function declaration. All functions should have a docstring.
- Accessing Docstrings: The docstrings can be accessed using the
__doc__method of the object or using the help function.
What is a break, continue, and pass in Python?
The break statement is used to terminate the loop or statement in which it is present. After that, the control will pass to the statements that are present after the break statement, if available.continue is also a loop control statement just like the break statement. continue statement is opposite to that of the break statement, instead of terminating the loop, it forces to execute the next iteration of the loop.pass means performing no operation or in other words, it is a placeholder in the compound statement, where there should be a blank left and nothing has to be written there.
How do you floor a number in Python?
The Python math module includes a method that can be used to calculate the floor of a number.
floor()method in Python returns the floor of x i.e., the largest integer not greater than x.- Also, The method
ceil(x)in Python returns a ceiling value of x i.e., the smallest integer greater than or equal to x.
What are global, protected and private attributes in Python?
- Global variables are public variables that are defined in the global scope. To use the variable in the global scope inside a function, we use the global keyword.
- Protected attributes are attributes defined with an underscore prefixed to their identifier eg. _sara. They can still be accessed and modified from outside the class they are defined in but a responsible developer should refrain from doing so.
- Private attributes are attributes with double underscore prefixed to their identifier eg. __ansh. They cannot be accessed or modified from the outside directly and will result in an AttributeError if such an attempt is made.
What is the use of self in Python?
self is used to represent the instance of the class. With this keyword, you can access the attributes and methods of an object inside the class definition in Python.
What is __init__ in Python?
__init__ is a contructor method in Python and is automatically called to allocate memory when a new object/instance is created. All classes have a __init__ method associated with them. It helps in distinguishing methods and attributes of a class from local variables.
What is slicing in Python?
- As the name suggests, ‘slicing’ is taking parts of a container.
- Syntax for slicing is
[start : stop : step] startis the starting index from where to slice a list or tuplestopis the ending index or where to stop.stepis the number of steps to jump.- Default value for start is 0, stop is number of items, step is 1.
- Slicing can be done on strings, arrays, lists, and tuples.
What is the difference between Python Arrays and Lists?
- Arrays in Python can only contain elements of same data types i.e., data type of array should be homogeneous. It is a thin wrapper around C language arrays and consumes far less memory than lists.
- Lists in Python can contain elements of different data types i.e., data type of lists can be heterogeneous. It has the disadvantage of consuming large memory.
Example:
import array
a = array.array('i', [1, 2, 3])
for i in a:
print(i, end=' ') #OUTPUT: 1 2 3
a = array.array('i', [1, 2, 'string']) #OUTPUT: TypeError: an integer is required (got type str)
a = [1, 2, 'string']
for i in a:
print(i, end=' ') #OUTPUT: 1 2 string
How is memory managed in Python?
- Memory management in Python is handled by the Python Memory Manager. The memory allocated by the manager is in form of a private heap space dedicated to Python. All Python objects are stored in this heap and being private, it is inaccessible to the programmer. Though, python does provide some core API functions to work upon the private heap space.
- Additionally, Python has an in-built garbage collection to recycle the unused memory for the private heap space.
What are Python namespaces? Why are they used?
A namespace in Python ensures that object names in a program are unique and can be used without any conflict. Python implements these namespaces as dictionaries with 'name as key' mapped to a corresponding 'object as value'. This allows for multiple namespaces to use the same name and map it to a separate object. A few examples of namespaces are as follows:
- Local Namespace includes local names inside a function. The namespace is temporarily created for a function call and gets cleared when the function returns.
- Global Namespace includes names from various imported packages/ modules that are being used in the current project. This namespace is created when the package is imported in the script and lasts until the execution of the script.
- Built-in Namespace includes built-in functions of core Python and built-in names for various types of exceptions.
The lifecycle of a namespace depends upon the scope of objects they are mapped to. If the scope of an object ends, the lifecycle of that namespace comes to an end. Hence, it isn't possible to access inner namespace objects from an outer namespace.
What are Decorators in Python?
Decorators in Python are essentially functions that add functionality to an existing function in Python without changing the structure of the function itself. They are represented the @decorator_name in Python and are called in a bottom-up fashion.
For example:
# decorator function to convert to lowercase
def lowercase_decorator(function):
def wrapper():
func = function()
string_lowercase = func.lower()
return string_lowercase
return wrapper
# decorator function to split words
def splitter_decorator(function):
def wrapper():
func = function()
string_split = func.split()
return string_split
return wrapper
@splitter_decorator # this is executed next
@lowercase_decorator # this is executed first
def hello():
return 'Hello World'
hello() # output => [ 'hello' , 'world' ]
The beauty of the decorators lies in the fact that besides adding functionality to the output of the method, they can even accept arguments for functions and can further modify those arguments before passing it to the function itself. The inner nested function, i.e. 'wrapper' function, plays a significant role here. It is implemented to enforce encapsulation and thus, keep itself hidden from the global scope.
# decorator function to capitalize names
def names_decorator(function):
def wrapper(arg1, arg2):
arg1 = arg1.capitalize()
arg2 = arg2.capitalize()
string_hello = function(arg1, arg2)
return string_hello
return wrapper
@names_decorator
def say_hello(name1, name2):
return 'Hello ' + name1 + '! Hello ' + name2 + '!'
say_hello('sara', 'ansh') # output => 'Hello Sara! Hello Ansh!'
How do you copy an object in Python?
In Python, the assignment statement (= operator) does not copy objects. Instead, it creates a binding between the existing object and the target variable name. To create copies of an object in Python, we need to use the copy module. Moreover, there are two ways of creating copies for the given object using the copy module:
- Shallow Copy is a bit-wise copy of an object. The copied object created has an exact copy of the values in the original object. If either of the values is a reference to other objects, just the reference addresses for the same are copied.
- Deep Copy copies all values recursively from source to target object, i.e. it even duplicates the objects referenced by the source object.
Examples:
from copy import copy, deepcopy
list_1 = [1, 2, [3, 5], 4]
## shallow copy
list_2 = copy(list_1)
list_2[3] = 7
list_2[2].append(6)
list_2 # output => [1, 2, [3, 5, 6], 7]
list_1 # output => [1, 2, [3, 5, 6], 4]
## deep copy
list_3 = deepcopy(list_1)
list_3[3] = 8
list_3[2].append(7)
list_3 # output => [1, 2, [3, 5, 6, 7], 8]
list_1 # output => [1, 2, [3, 5, 6], 4]
What is pickling and unpickling?
Python library pickle offers a feature - serialization out of the box. Serializing an object refers to transforming it into a format that can be stored, so as to be able to deserialize it, later on, to obtain the original object. Here, the pickle module comes into play.
What are Generators in Python?
Generators are functions that return an iterable collection of items, one at a time, in a set manner. Generators, in general, are used to create iterators with a different approach. They employ the use of ´´yield´´ keyword rather than ´´return`` to return a generator object.
Let's try and build a generator for fibonacci numbers:
## generate fibonacci numbers upto n
def fib(n):
p, q = 0, 1
while(p < n):
yield p
p, q = q, p + q
x = fib(10) # create generator object
## iterating using __next__(), for Python2, use next()
x.__next__() # output => 0
x.__next__() # output => 1
x.__next__() # output => 1
x.__next__() # output => 2
x.__next__() # output => 3
x.__next__() # output => 5
x.__next__() # output => 8
x.__next__() # error
## iterating using loop
for i in fib(10):
print(i) # output => 0 1 1 2 3 5 8
What is the difference between .py and .pyc files?
- .py files contain the source code of a program. Whereas, .pyc file contains the bytecode of your program. We get bytecode after compilation of .py file (source code). .pyc files are not created for all the files that you run. It is only created for the files that you import.
- Before executing a python program python interpreter checks for the compiled files. If the file is present, the virtual machine executes it. If not found, it checks for .py file. If found, compiles it to .pyc file and then python virtual machine executes it.
- Having .pyc file saves you the compilation time.
How Python is interpreted?
- Python as a language is not interpreted or compiled. Interpreted or compiled is the property of the implementation. Python is a bytecode(set of interpreter readable instructions) interpreted generally.
- Source code is a file with .py extension.
- Python compiles the source code to a set of instructions for a virtual machine. The Python interpreter is an implementation of that virtual machine. This intermediate format is called “bytecode”.
- .py source code is first compiled to give .pyc which is bytecode. This bytecode can be then interpreted by the official CPython or JIT(Just in Time compiler) compiled by PyPy.
What are iterators in Python?
- An iterator is an object.
- It remembers its state i.e., where it is during iteration (see code below to see how)
__iter__()method initializes an iterator.- It has a
__next__()method which returns the next item in iteration and points to the next element. Upon reaching the end of iterable object__next__()must return StopIteration exception. - It is also self-iterable.
- Iterators are objects with which we can iterate over iterable objects like lists, strings, etc.
Example:
class ArrayList:
def __init__(self, number_list):
self.numbers = number_list
def __iter__(self):
self.pos = 0
return self
def __next__(self):
if(self.pos < len(self.numbers)):
self.pos += 1
return self.numbers[self.pos - 1]
else:
raise StopIteration
array_obj = ArrayList([1, 2, 3])
it = iter(array_obj)
print(next(it)) #output: 2
print(next(it)) #output: 3
print(next(it))
#Throws Exception
#Traceback (most recent call last):
#...
#StopIteration
What are negative indexes and why are they used?
- Negative indexes are the indexes from the end of the list or tuple or string.
- Arr[-1] means the last element of array Arr[].
Example:
arr = [1, 2, 3, 4, 5, 6]
#get the last element
print(arr[-1]) #output 6
#get the second last element
print(arr[-2]) #output 5
Which sorting technique is used by sort() and sorted() functions of python?
Python uses the TimSort algorithm for sorting. It’s a stable sorting whose worst case is O(N log N). It’s a hybrid sorting algorithm, derived from MergeSort and InsertionSort, designed to perform well on many kinds of real-world data.
How do you create a class in Python?
To create a class in python, we use the keyword “class” as shown in the example below:
class Employee:
def __init__(self, emp_name):
self.emp_name = emp_name
To instantiate or create an object from the class created above, we do the following:
emp_1=Employee("Mr. Employee")
To access the name attribute, we just call the attribute using the dot operator as shown below:
print(emp_1.emp_name)
To create methods inside the class, we include the methods under the scope of the class as shown below:
class Employee:
def __init__(self, emp_name):
self.emp_name = emp_name
def introduce(self):
print("Hello I am " + self.emp_name)
The self parameter has to be the first parameter of any method defined inside the class. The method of the class Employee can be accessed as shown below:
emp_1.introduce()
How does inheritance work in python? Explain it with an example.
Inheritance gives the power to a class to access all attributes and methods of another class. It aids in code reusability and helps the developer to maintain applications without redundant code. The class inheriting from another class is a child class or also called a derived class. The class from which a child class derives the members are called parent class or superclass.
Python supports different kinds of inheritance, they are:
- Single Inheritance: Child class derives members of one parent class.
# Parent class
class ParentClass:
def par_func(self):
print("I am parent class function")
# Child class
class ChildClass(ParentClass):
def child_func(self):
print("I am child class function")
# Driver code
obj1 = ChildClass()
obj1.par_func()
obj1.child_func()
- Multi-level Inheritance: The members of the parent class, A, are inherited by child class which is then inherited by another child class, B. The features of the base class and the derived class are further inherited into the new derived class, C. Here, A is the grandfather class of class C.
# Parent class
class A:
def __init__(self, a_name):
self.a_name = a_name
# Intermediate class
class B(A):
def __init__(self, b_name, a_name):
self.b_name = b_name
# invoke constructor of class A
A.__init__(self, a_name)
# Child class
class C(B):
def __init__(self,c_name, b_name, a_name):
self.c_name = c_name
# invoke constructor of class B
B.__init__(self, b_name, a_name)
def display_names(self):
print("A name : ", self.a_name)
print("B name : ", self.b_name)
print("C name : ", self.c_name)
# Driver code
obj1 = C('child', 'intermediate', 'parent')
print(obj1.a_name)
obj1.display_names()
- Multiple Inheritance: This is achieved when one child class derives members from more than one parent class. All features of parent classes are inherited in the child class.
# Parent class1
class Parent1:
def parent1_func(self):
print("Hi I am first Parent")
# Parent class2
class Parent2:
def parent2_func(self):
print("Hi I am second Parent")
# Child class
class Child(Parent1, Parent2):
def child_func(self):
self.parent1_func()
self.parent2_func()
# Driver's code
obj1 = Child()
obj1.child_func()
- Hierarchical Inheritance: When a parent class is derived by more than one child class, it is called hierarchical inheritance.
# Base class
class A:
def a_func(self):
print("I am from the parent class.")
# 1st Derived class
class B(A):
def b_func(self):
print("I am from the first child.")
# 2nd Derived class
class C(A):
def c_func(self):
print("I am from the second child.")
# Driver's code
obj1 = B()
obj2 = C()
obj1.a_func()
obj1.b_func() #child 1 method
obj2.a_func()
obj2.c_func() #child 2 method
How do you access parent members in the child class?
Following are the ways using which you can access parent class members within a child class:
- By using Parent class name: You can use the name of the parent class to access the attributes as shown in the example below:
class Parent(object):
# Constructor
def __init__(self, name):
self.name = name
class Child(Parent):
# Constructor
def __init__(self, name, age):
Parent.name = name
self.age = age
def display(self):
print(Parent.name, self.age)
# Driver Code
obj = Child("Interviewbit", 6)
obj.display()
- By using
super(): The parent class members can be accessed in child class using thesuperkeyword.
class Parent(object):
# Constructor
def __init__(self, name):
self.name = name
class Child(Parent):
# Constructor
def __init__(self, name, age):
'''
In Python 3.x, we can also use super().__init__(name)
'''
super(Child, self).__init__(name)
self.age = age
def display(self):
# Note that Parent.name cant be used
# here since super() is used in the constructor
print(self.name, self.age)
# Driver Code
obj = Child("Interviewbit", 6)
obj.display()
Are access specifiers used in python?
Python does not make use of access specifiers specifically like private, public, protected, etc. However, it does not derive this from any variables. It has the concept of imitating the behaviour of variables by making use of a single (protected) or double underscore (private) as prefixed to the variable names. By default, the variables without prefixed underscores are public.
Is it possible to call parent class without its instance creation?
Yes, it is possible if the base class is instantiated by other child classes or if the base class is a static method.
How is an empty class created in python?
An empty class does not have any members defined in it. It is created by using the pass keyword (the pass command does nothing in python). We can create objects for this class outside the class.
What is Polymorphism in Python?
Polymorphism means the ability to take multiple forms. So, for instance, if the parent class has a method named ABC then the child class also can have a method with the same name ABC having its own parameters and variables. Python allows polymorphism.
Differentiate between new and override modifiers.
The new modifier is used to instruct the compiler to use the new implementation and not the base class function. The override modifier is useful for overriding a base class function inside the child class.
How will you check if a class is a child of another class?
This is done by using a method called issubclass() provided by python. The method tells us if any class is a child of another class by returning true or false accordingly.
Define encapsulation in Python?
Encapsulation means binding the code and the data together. A Python class is an example of encapsulation.
How do you do data abstraction in Python?
Data Abstraction is providing only the required details and hides the implementation from the world. It can be achieved in Python by using interfaces and abstract classes.
Give an example of Multithreading with Threads Synchronization in Python.
The following code gives an example of threads synchronaization in Python:
import threading
# global variable x
x = 0
def increment():
"""
function to increment global variable x
"""
global x
x += 1
def thread_task(lock):
"""
task for thread
calls increment function 100000 times.
"""
for _ in range(100000):
lock.acquire()
increment()
lock.release()
def main_task():
global x
# setting global variable x as 0
x = 0
# creating a lock
lock = threading.Lock()
# creating threads
t1 = threading.Thread(target=thread_task, args=(lock,))
t2 = threading.Thread(target=thread_task, args=(lock,))
# start threads
t1.start()
t2.start()
# wait until threads finish their job
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(10):
main_task()
print("Iteration {0}: x = {1}".format(i,x))
Output:
Iteration 0: x = 200000
Iteration 1: x = 200000
Iteration 2: x = 200000
Iteration 3: x = 200000
Iteration 4: x = 200000
Iteration 5: x = 200000
Iteration 6: x = 200000
Iteration 7: x = 200000
Iteration 8: x = 200000
Iteration 9: x = 200000
Give an example of Threads Synchronization with Condition Variables.
Consider the following example:
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-9s) %(message)s',)
def consumer(cv):
logging.debug('Consumer thread started ...')
with cv:
logging.debug('Consumer waiting ...')
cv.wait()
logging.debug('Consumer consumed the resource')
def producer(cv):
logging.debug('Producer thread started ...')
with cv:
logging.debug('Making resource available')
logging.debug('Notifying to all consumers')
cv.notifyAll()
if __name__ == '__main__':
condition = threading.Condition()
cs1 = threading.Thread(name='consumer1', target=consumer, args=(condition,))
cs2 = threading.Thread(name='consumer2', target=consumer, args=(condition,))
pd = threading.Thread(name='producer', target=producer, args=(condition,))
cs1.start()
time.sleep(2)
cs2.start()
time.sleep(2)
pd.start()
Output:
(consumer1) Consumer thread started ...
(consumer1) Consumer waiting ...
(consumer2) Consumer thread started ...
(consumer2) Consumer waiting ...
(producer ) Producer thread started ...
(producer ) Making resource available
(producer ) Notifying to all consumers
(consumer1) Consumer consumed the resource
(consumer2) Consumer consumed the resource
Give an example of using ThreadPoolExecuter in Python.
Consider the following:
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://nonexistant-subdomain.python.org/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
Give an example of using ProcessPoolExecuter.
The following code describes such a use case:
import concurrent.futures
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
Explain the difference between Thread and Process in Python.
A Process is an instance of a program, e.g. a Python interpreter. They are independent from each other and do not share the same memory.
Key facts: - A new process is started independently from the first process - Takes advantage of multiple CPUs and cores - Separate memory space - Memory is not shared between processes - One GIL (Global interpreter lock) for each process, i.e. avoids GIL limitation - Great for CPU-bound processing - Child processes are interruptable/killable
- Starting a process is slower that starting a thread
- Larger memory footprint
- IPC (inter-process communication) is more complicated
A Thread is an entity within a process that can be scheduled for execution (Also known as "leightweight process"). A Process can spawn multiple threads. The main difference is that all threads within a process share the same memory.
Key facts: - Multiple threads can be spawned within one process - Memory is shared between all threads - Starting a thread is faster than starting a process - Great for I/O-bound tasks - Leightweight - low memory footprint
- One GIL for all threads, i.e. threads are limited by GIL.
- Multithreading has no effect for CPU-bound tasks due to the GIL.
- Not interruptible/killable -> be careful with memory leaks.
- Increased potential for race conditions.
What is the Python Global Interpreter Lock (GIL)?
Python Global Interpreter Lock (GIL) is a type of process lock which is used by python whenever it deals with processes. Generally, Python only uses only one thread to execute the set of written statements. This means that in python only one thread will be executed at a time. The performance of the single-threaded process and the multi-threaded process will be the same in python and this is because of GIL in python. We can not achieve multithreading in python because we have global interpreter lock which restricts the threads and works as a single thread.
Interview questions for algorithms and data structures.
Sources:
www.wikipedia.com
www.geeksforgeeks.org
www.simplilearn.com/data-structure-interview-questions-and-answers-article
www.herovired.com/learning-hub/blogs/arrays-in-data-structure/#basic-operations
www.tutorialspoint.com/data_structures_algorithms/hash_data_structure.htm
www.masaischool.com/blog/tree-data-structure-types-operations-applications/
www.vinayakd.com/articles/delete-n-ary-tree-node
What is a Data Structure?
In computer science, a data structure is a data organization, and storage format that is usually chosen for efficient access to data.
Describe the types of Data Structures?
- Array - an array is a number of elements in a specific order, typically all of the same type. Elements are accessed using an integer index to specify which element is required.
- List - a linked list is a linear collection of data elements of any type, called nodes, where each node has itself a value, and points to the next node in the linked list. The principal advantage of a linked list over an array is that values can always be efficiently inserted and removed without relocating the rest of the list. Certain other operations, such as random access to a certain element, are however slower on lists than on arrays.
- Record - a record (also called tuple or struct) is an aggregate data structure. A record is a value that contains other values, typically in fixed number and sequence and typically indexed by names. The elements of records are usually called fields or members. In the context of object-oriented programming, records are known as plain old data structures to distinguish them from objects.
- Hash tables - also known as hash maps, are data structures that provide fast retrieval of values based on keys. They use a hashing function to map keys to indexes in an array, allowing for constant-time access in the average case. Hash tables are commonly used in dictionaries, caches, and database indexing. However, hash collisions can occur, which can impact their performance. Techniques like chaining and open addressing are employed to handle collisions.
- Graphs - collections of nodes connected by edges, representing relationships between entities. They consist of vertices (nodes) and edges (connections between nodes). Graphs can be directed or undirected, and they can have cycles or be acyclic.
- Stacks and queues - abstract data types that can be implemented using arrays or linked lists. A stack has two primary operations: push (adds an element to the top of the stack) and pop (removes the topmost element from the stack), that follow the Last In, First Out (LIFO) principle. Queues have two main operations: enqueue (adds an element to the rear of the queue) and dequeue (removes an element from the front of the queue) that follow the First In, First Out (FIFO) principle.
- Trees - represent a hierarchical organization of elements. A tree consists of nodes connected by edges, with one node being the root and all other nodes forming subtrees. Binary trees (particularly heaps), AVL trees, and B-trees are some popular types of trees. They enable efficient and optimal searching, sorting, and hierarchical representation of data.
- Trie - also known as a prefix tree, is a specialized tree data structure used for the efficient retrieval of strings. Tries store characters of a string as nodes, with each edge representing a character. They are particularly useful in text processing scenarios like autocomplete, spell-checking, and dictionary implementations. Tries enable fast searching and prefix-based operations on strings.
What is a Linear Data Structure? Name a few examples.
A data structure is linear if all its elements or data items are arranged in a sequence or a linear order. The elements are stored in a non-hierarchical way so that each item has successors and predecessors except the first and last element in the list. Examples of linear data structures are Array, Stack, Queue, and Linked List.
How are the elements of a 2D Array stored in the memory.
- Row-Major Order: In row-major ordering, the first row of a 2D array is entirely stored in memory, followed by the second row of the array, and so on until the final row.
- Column-Major Order: In column-major ordering, the first column of the array is entirely saved in memory, followed by the second row of the array, and so on until the last column of the array is fully recorded in the memory.
What are some use cases for Row-Major and Column-Major storing of 2D Arrays?
Row-Major stored arrays are more efficient for row-wise access like in Image Processing. Column-Major stored arrays are more efficient for column-wise access like for Matrix Multiplication.
How can you possibly choose between Row-Major and Column-Major 2D Arrays storing implementations?
By choosing a programming language. Row-Major is implemented in languages like C/C++ and Column-Major - in Fortran.
What is a Linked List Data Structure?
It’s a both linear and non-linear Data Structure, depending on application, or a sequence of data objects where elements are not stored in adjacent memory locations. The elements are linked using pointers to form a chain. Each element is a separate object, called a node. Each node has two items: a data field and a reference to the next node. The entry point in a linked list is called the head. Where the list is empty, the head is a null reference and the last node has a reference to null. A linked list is a dynamic data structure, where the number of nodes is not fixed, and the list has the ability to grow and shrink on demand. It is applied in cases where:
- We deal with an unknown number of objects or don’t know how many items are in the list
- We need constant-time insertions/deletions from the list, as in real-time computing where time predictability is critical
- Random access to any elements is not needed
- The algorithm requires a data structure where objects need to be stored irrespective of their physical address in memory
- We need to insert items in the middle of the list as in a priority queue
Are Linked Lists considered Linear or Non-linear Data Structures?
Linked lists are considered both linear and non-linear data structures depending upon the application they are used for. When used for access strategies, it is considered as a linear data-structure. When used for data storage, it is considered a non-linear data structure.
What are the advantages of a Linked List over an Array? In which scenarios do we use Linked List and when Array?
Advantages of a linked list over an array are:
Insertion and Deletion
Insertion and deletion of nodes is an easier process, as we only update the address present in the next pointer of a node. It’s expensive to do the same in an array as the room has to be created for the new elements and existing elements must be shifted.Dynamic Data Structure
As a linked list is a dynamic data structure, there is no need to give an initial size as it can grow and shrink at runtime by allocating and deallocating memory. However, the size is limited in an array as the number of elements is statically stored in the main memory.No wastage of Memory
As the size of a linked list can increase or decrease depending on the demands of the program, and memory is allocated only when required, there is no memory wasted. In the case of an array, there is memory wastage. For instance, if we declare an array of size 10 and store only five elements in it, then the space for five elements is wasted.Implementation
Data structures like stack and queues are more easily implemented using a linked list than an array.Some scenarios where we use linked list over array are:
- When we do not know the upper limit on the number of elements in advance
- When there are a large number of add or remove operations
- When there are no large number of random access to elements
- When we want to insert items in the middle of the list, such as when implementing a priority queue
Some scenarios in which we use array over the linked list are:
- When we need to index or randomly access elements
- When we know the number of elements in the array beforehand, so we can allocate the correct amount of memory
- When we need speed when iterating through all the elements in the sequence
- When memory is a concern; filled arrays use less memory than linked lists, as each element in the array is the data but each linked list node requires the data as well as one or more pointers to the other elements in the linked list
What is a Doubly-Linked List?
It is a complex type (double-ended LL) of a linked list in which a node has two links, one that connects to the next node in the sequence and another that connects to the previous node. This allows traversal across the data elements in both directions.
What are Dynamic Data Structures? Name a few.
They are collections of data in memory that expand and contract to grow or shrink in size as a program runs. This enables the programmer to control exactly how much memory is to be utilized. Examples are the dynamic array, linked list, stack, queue, and heap.
What is a Stack?
A stack is an abstract data type that specifies a linear data structure, as in a real physical stack or piles where you can only take the top item off the stack in order to remove things. Thus, insertion (push) and deletion (pop) of items take place only at one end called top of the stack, with a particular order: LIFO (Last In First Out) or FILO (First In Last Out).
Where are Stacks used?
- Expression, evaluation, or conversion of evaluating prefix, postfix, and infix expressions
- Syntax parsing
- String reversal
- Parenthesis checking
- Backtracking
What are the operations that can be performed on a Stack?
A stack may perform three fundamental operations:
- PUSH: The push action inserts a new element into the stack. The new feature is placed at the top of the stack.
- POP: The pop operation is performed to remove the stack's topmost element.
- PEEK: A peek action returns the value of the stack's topmost element without removing it from the stack.
What is a queue Data Structure?
A queue is an abstract data type that specifies a linear data structure or an ordered list, using the First In First Out (FIFO) operation to access elements. Insert operations can be performed only at one end called REAR and delete operations can be performed only at the other end called FRONT.
List some applications of the Queue Data Structure.
To prioritize jobs as in the following scenarios:
- As waiting lists for a single shared resource (like printer, CPU, call center systems).
- In the asynchronous transfer of data (file IO, sockets).
What is a Dequeue?
It is a double-ended queue, or a data structure, where the elements can be inserted or deleted at both ends (FRONT and REAR).
What operations can be performed on Queues?
- enqueue() adds an element to the end of the queue
- dequeue() removes an element from the front of the queue
- init() is used for initializing the queue
- isEmpty() tests for whether or not the queue is empty
- The front is used to get the value of the first data item but does not remove it
- The rear is used to get the last item from a queue
Define the Graph Data Structure.
It is a type of non-linear data structure that consists of vertices or nodes connected by edges or arcs to enable storage or retrieval of data. Edges may be directed or undirected.
What are the applications of Graph Data Structures?
- Transport grids where stations are represented as vertices and routes as the edges of the graph
- Utility graphs of power or water, where vertices are connection points and edge the wires or pipes connecting them
- Social network graphs to determine the flow of information and hotspots (edges and vertices)
- Neural networks where vertices represent neurons and edge the synapses between them
List the types of Trees?
The General Tree
A tree is referred to as a generic tree if its hierarchy is not constrained. In the General Tree, each node can have an endless number of offspring, and all other trees are subsets of the tree.The Binary Tree
The binary tree is a type of tree in which each parent has at least two offspring. The children are referred to as the left and right youngsters. This tree is more popular than most others. When specific limitations and features are given to a Binary tree, various trees such as AVL tree, BST (Binary Search Tree), RBT tree, and so on are also utilized.Binary Search Tree
Binary Search Tree (BST) is a binary tree extension that includes numerous optional constraints. In BST, a node's left child value should be less than or equal to the parent value, while the right child value should always be higher than the parent's value.The AVL Tree
The AVL tree is a self-balancing binary search tree (automatically keeps its height (maximal number of levels below the root) small in the face of arbitrary item insertions and deletions). The term AVL is given in honor of the inventors Adelson-Velshi and Landis. This was the first tree to achieve dynamic equilibrium. Each node in the AVL tree is assigned a balancing factor based on whether the tree is balanced or not. The node kids have a maximum height of one AVL vine. Search, insert, delete operations have O(log n) complexity.Red and Black Tree
Red-black trees are another type of auto-balancing tree. The red-black term is derived from the qualities of the red-black tree, which has either red or black painted on each node. It helps to keep the forest in balance. Even though this tree is not perfectly balanced, the searching process takes just O(log n) time.The N-ary Tree
In this sort of tree with a node, N is the maximum number of children. A binary tree is a two-year tree since each binary tree node has no more than two offsprings. A full N-ary tree is one in which the children of each node are either 0 or N.Octree
An octree is a tree data structure in which each internal node has exactly eight children. Octrees are most often used to partition a three-dimensional space by recursively subdividing it into eight octants.Heap
A heap is a tree-based data structure that satisfies the heap property: in a max heap, for any given node C, if P is a parent node of C, then the key (the value) of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C.
How is a Node Height in the Tree Data Structure determined?
The height of a node is the number of edges from that node to the leaf node (the lowermost node in the hierarchy).
How is a Node Depth in the Tree Data Structure determined?
The depth of a node is the number of edges it takes from the root (the uppermost node in the hierarchy) node to that particular node.
What is a Node Degree in the Tree Data Structure?
The total number of branches coming out of a node is considered to be the degree of that node.
What is a Forest in relation with the Tree Data Structure?
A collection of disconnected trees is called a forest. If you cut the root of a tree, the disjoint trees hence formed make up a forest.
How is a Balanced Binary Tree determined?
A balanced binary tree, also referred to as a height-balanced binary tree, is defined as a binary tree in which the height of the left and right subtree of any node differ by not more than 1.
What is a Self-balancing Binary Tree?
Self-Balancing Binary Search Trees are height-balanced binary search trees that automatically keep the height as small as possible when insertion and deletion operations are performed on the tree. Most prominent examples are AVL Trees and Red-Black Trees.
What is a B-Tree Data Structure?
A B-tree is a sort of self-balancing search tree whereby each node could have more than two children and hold multiple keys.
Explain what Jagged Array is?
It is an array whose elements themselves are arrays and may be of different dimensions and sizes.
What is an Algorithm?
An algorithm is a step by step method of solving a problem or manipulating data. It defines a set of instructions to be executed in a certain order to get the desired output.
What is an asymptotic analysis of an algorithm?
Asymptotic analysis is the technique of determining an algorithm's running time in mathematical units to determine the program's limits, also known as "run-time performance." The purpose is to identify the best case, worst case, and average-case times for completing a particular activity.
What are Asymptotic Notations?
Asymptotic Notation represents an algorithm's running time - how long an algorithm takes with a given input, n. Big O, big Theta, and big Omega are the three distinct notations. When the running time is the same in all circumstances, big-Theta is used, big-O for the worst-case running time, and big-Omega for the best case running time.
What are the common algorithmic runtimes in big O notation?
- Constant - O(1) (Insertion in a linked list)
- Logarithmic - O(log(N)) (Binary Search)
- Linear - O(N) (Linear Search)
- Polynomial - O(N^b) (QuickSort with O(N*log(N)))
- Exponential - O(b^N) (Fibonacci series (each element is a sum of previous two) without Dynamic Programming, (O(N) with dynamic programming))
- Factorial - O(N!) (Generation of all possible permutations of N objects)
What are basic operations on Arrays?
- Traversing - looping through each element in the array and processing each element one at a time.
- Insertion - the process of adding new elements into an existing array. This can be done by providing an index for where the insertion should occur and then shifting other elements in the array to make space for the insertion.
- Deletion - the opposite of insertion and involves removing elements from an existing array. After deleting an element, all other elements in the array must be shifted to fill any gaps left from deletion.
- Searching - process of identifying an element from within an array by comparing it to your desired value until you find a match.
- Sorting - process of arranging elements of an array in either ascending or descending order.
What are the basic types of searching? Describe their worst case asymptotic behaviour.
- Linear Search - compares each element one after another until a match is found, or all elements have been searched. It has O(n) time complexity, because in worst case the searched element is the last one, or there is no such elements and you go through whole array.
- Binary Search - can be done in sorted arrays by comparing the middle element with the target and if they are not equal, the half where the target cannot lie is elemenated. The time complexity is O(log2(N)), because with each step you divide the number of elements N by 2, like N/2, N/4, N/8... until you reach 1. So N/2^k = 1 and thus k = log2(N).
What are some common array sorting algorithms?
- PermutationSort - most ineffective sorting algorithm. It works by generating permutations of an array and checking if it is in the right sorted order. The worst case time complexity is O(?) undefined, since it has no upper bound and could run forever.
- BubbleSort - simple and easy to understand sorting algorithm. Consists of two loops. In the case of sorting in ascending order, the inner loop goes over elements and if an element is bigger than the next one, they are swapped. The outer loop repeats the procedure. The time complexity is O(N^2). Still too slow for real life problems.
- QuickSort - the fastest sorting algorithm based on divide and conquer principle. The key process in QuickSort is a Partition. The target of partitions is to place the pivot (any element can be chosen to be a pivot) at its correct position in the sorted array and put all smaller elements to the left of the pivot, and all greater elements to the right of the pivot. Partition is done recursively on each side of the pivot after the pivot is placed in its correct position and this finally sorts the array. The time complexity is O(N*log(N)).
- InsertionSort - is a simple sorting algorithm that works by iteratively inserting each element of an unsorted list into its correct position in a sorted portion of the list. It is a stable sorting algorithm, meaning that elements with equal values maintain their relative order in the sorted output. Insertion sort is like sorting playing cards in your hands. You split the cards into two groups: the sorted cards and the unsorted cards. Then, you pick a card from the unsorted group and put it in the right place in the sorted group. It has the worst-case time-complexity of O(N^2).
- HeapSort - is a comparison-based sorting technique based on Binary Heap data structure.
- Build a heap from the given input array.
- Repeat the following steps until the heap contains only one element:
- Swap the root element of the heap (which is the largest element) with the last element of the heap.
- Remove the last element of the heap (which is now in the correct position).
- Heapify the remaining elements of the heap in top-down order.
- The sorted array is obtained by reversing the order of the elements in the input array.
Name the main properties of the basic operations on linked lists.
- Traversing - this operation has a time complexity of O(N), the same as for arrays. But one can not access elemnts of a linked list by direct indexing.
- Insertion - this operation has a constant time complexity in contrast to arrays, where the worst case time complexity of the operation is O(N). It needs only to modify pointers in the chain at the place of insertion.
- Deletion - the mechanism is the same as for Insertion.
- Search - the same as for an Array in the case of an unsorted list, the worst case time complexity of searching an element is O(N). Binary search can be done only for sorted lists.
- Sort - the same algorithms as for Arrays can be applied for linked lists with the time complexity depending on the chosen algorithm.
How can one detect loops in a Linked Lists, name a few approaches?
- Floyd's Loop Detection Algorithm - uses two pointers running over a linked list with different velocities, like first goes over each element, the second jumps over one element. If there are loops in the linked list, the two pointers will be equal at some point in the loop. Otherwise, the both reach the last element in the list.
- Using Hashing - traverse the linked list and save the calculated hash of each node's adress. If the current node's hash points to one of the previously calculated hashes, then the list has loops. If the last element is reached without pointing to the previous hashes, then there are no loops.
Give some examples of basic Hash Functions that can be used in Hash Table Data Structure?
- Division - a modulus function that returns the division remainder is used in this case. A key value is divided by the table length and the remainder is used as an index in the table.
- Mid Square - in this case the key value is squared and the middle N digits are extracted as a hash value.
- Digit Folding - divide the key value into a number of parts, where each part has the same number of digits, except for the last one. Addition of the parts gives a hash number.
- Multiplication - choose a constant value between 0 and 1. Multiply it with the key value. Extract the fractional part of the multiplication product. Multiply it by the hash table length and take the floor of the result. This produces the hash.
How can one possibly avoid Hash Collisions in Hash Tables?
One could solve the problem of hash collisions by for example Linear Probing. If the calculated index in a hash table is already in use, one just searches for the next empty cell in the table.
What are the basic operations on Hash Tables?
- Search - compute the hash of a passed key and locate the value by hash code as an array index. If the element is not found use linear probing to get the element ahead.
- Insert - compute the hash code of a passed key. Use cash code as an index in the array. If the cell is not empty use linear probing to get to the next empty cell.
- Delete - the same as for previous operations hash code is used as an array index. If the cell is empty use linear probing to get to the element ahead. Once the lement is found store a dummy element there.
What is a Bipartite Graph?
A bipartite graph (or bigraph) is a graph whose vertices can be divided into two disjoint and independent sets U and V, that is, every edge connects a vertex in U to one in V . Vertex sets U and V are usually called the parts of the graph. Equivalently, a bipartite graph is a graph that does not contain any odd-length cycles.
What is a Weighted Graph?
A graph whose vertices or edges have been assigned weights. A vertex-weighted graph has weights on its vertices and an edge-weighted graph has weights on its edges.
What is a Directed Graph?
A directed graph (or digraph) is a graph that is made up of a set of vertices connected by directed edges, often called arcs.
What is a Transpose of a Directed Graph?
Transpose of a directed graph G is another directed graph on the same set of vertices with all of the edges reversed compared to the orientation of the corresponding edges in G.
What is a Strongly Connected Graph?
A directed graph is called strongly connected if there is a path from each vertex in the graph to every other vertex.
What is a Minimum Spanning Tree of a Graph?
A minimum spanning tree (MST) is defined as a spanning tree that has the minimum weight among all the possible spanning trees. A Spanning Tree is a subset of the edges of the graph that forms a tree (acyclic) where every node of the graph is a part of the tree.
Name the ways of representing and storing a Graph Data Structure.
- Adjacency Matrix - in this method a graph is represented in the form of a 2D matrix, where rows and columns denote vertices. And the values in the cells describe reletionships (edges) between vertices.
- Adjacency List - here a Graph is represented as a collection of linked lists. There is an array of pointers for all vertices. Each pointer shows connections to all other vertices in a chain that have edges to the reference vertice. When a Graph has a lot of edges, then it is better to represent it in the form of Adjacency Matrix.
| Action | Adjacency Matrix | Adjacency List |
| Adding Edge | O(1) | O(1) |
| Removing Edge | O(1) | O(N) |
| Initializing | O(N*N) | O(N) |
What are the basic operations on Graphs?
- Insertion of Nodes/Edges in the graph.
- Deletion of Nodes/Edges in the graph.
- Searching on Graphs – Search an entity in the graph.
- Traversal of Graphs – Traversing all the nodes in the graph.
List the ways of Traversing a Graph.
- Breadth-First-Search - is a graph traversal algorithm that explores all the vertices in a graph at the current depth before moving on to the vertices at the next depth level. It starts at a specified vertex and visits all its neighbors before moving on to the next level of neighbors. To avoid processing a node more than once, we divide the vertices into two categories: Visited and Not visited. It has time complexity of O(V+E), where V is a number of vertices and E - of edges.
- Depth-First-Search - the algorithm starts selecting some arbitrary node as the root node and explores as far as possible along each branch before backtracking. To avoid processing a node more than once, we divide the vertices into two categories: Visited and Not visited. It has time complexity of O(V+E), where V is a number of vertices and E - of edges.
List the main applications of Breadth-First-Search.
- Shortest Path Finding - Breadth-First-Search can be used to find the shortest path between two nodes in an unweighted graph. By keeping track of the parent of each node during the traversal, the shortest path can be reconstructed.
- Cycle Detection - Breadth-First-Search can be used to detect cycles in a graph. If a node is visited twice during the traversal, it indicates the presence of a cycle.
- Connected Components - Breadth-First-Search can be used to identify connected components in a graph. Each connected component is a set of nodes that can be reached from each other.
- Topological Sorting - BFS can be used to perform topological sorting on a directed acyclic graph (DAG). Topological sorting arranges the nodes in a linear order such that for any edge (u, v), u appears before v in the order.
List the main applications of Depth-First-Search.
- Detecting Cycle in a Graph - A graph has a cycle if and only if we see a back edge during DFS. So we can run DFS for the graph and check for back edges.
- Path Finding - Depth-First-Search can be used to find a path between any two vertices. Choose one vertex es a start. Use stack in order to save the path between starting and current vertex. As son as destination vertex is reached, return the path.
- Topological Sorting - the same like for Breadth-First-Search, it is used mainly for jobs scheduling from the given dependencies among jobs.
- Testing if a Graph is Bipartite - when we first discover a new vertex, color it opposite its parents, and for each other edge, check it doesn’t link two vertices of the same color. The first vertex in any connected component can be red or black.
- Finding Strongly Connected Components in a Graph - for example brute-force checking if the definition of a strongly connected component fits the vertices of a graph.
- Backtracking - Depth-first search can be used in backtracking algorithms.
What are the basic operations on Trees Data Structures?
- Traversal - a hierarchical data structure like a tree can have different ways of traversal. Simplifying to a Binary Tree, one can distinguish between three types of traversal:
- In-order - it starts with visiting all the nodes in the left subtree. Then visits the root node. And finally, all the nodes in the right subtree are visited.
- Pre-order - first the root node is visited. Then all the nodes in the left subtree. And finally visits all the nodes in the right subtree.
- Post-order - starts with the nodes in the left subtree. Visits the nodes in the right subtree. And then visits the root node.
- Level-order - defined as a method to traverse a Tree such that all nodes present in the same level are traversed completely before traversing the next level.
- Insertion - insertion can be done in general at the leftmost, rightmost or the first vacant position found during traversal.
- Search - is conducted in the form of a Binary Search for Binary Trees. For General Trees a Depth-First-Search like in the case of Graphs can be used. The search is implemented as a recursive function.
- Deletion - during deletion there are 4 options to look at, the node either:
- Is a leaf node (has no children).
- Has only one child, which then will take place of the deleted one.
- Has more than 1 child and we want to promote them all. The root of the deleted node will become the root of all children nodes of the deleted one.
- Has more than 1 child and we want to promote only one of them. Thus only one node takes the place of the deleted one and becomes root for the rest of the children nodes.
Explain the mechanism of Self-Balancing in AVL Trees.
First the Balance Factor of all nodes is calculated as a difference between the height of the left branch and the height of the right branch. If the balance factor is -1,0 or 1 then the tree is balanced, otherwise left and right rotations of the nodes must be done in order to shorten the height of branches with single nodes. During rotations the fundamental property of binary trees must be satisfied that the right child node is bigger than the parent and the left one is smaller. After rotations balance factors are calculated again and if they are -1,0 or 1 a new element can be inserted. Otherwise rotations are conducted further until balanced state is achieved.
Explain the mechanism of Self-Balancing in Red-Black Trees.
The fundamental rules of Red-Black Trees are:
1. Every node has a color either red or black.
2. The root of the tree is always black.
3. There are no two adjacent red nodes (A red node cannot have a red parent or red child).
4. Every path from a node (including root) to any of its descendants NULL nodes has the same number of black nodes.
5. Every leaf (e.i. NULL node) must be colored BLACK.
After insertion two basic operations are used in order to ensure the balance: Rotation and Recolouring. First, an element is inserted like in general binary trees and coloured red. One tries first the recolouring during balancing and if it does not work, rotations are conducted. If the new node (child) appears to be the root it is recoloured in black (see properties). Check the colour of the parent (father) node. If it is black then left the colour of the child node as red. If the father is also red, check the colour of its opposite node (uncle) on the same level. If the color of this node is also red then change both father and uncle nodes to black and the grandfather (parent node of father and uncle) to red if its not the root node, otherwise do not change the grandfathers color. Repeat the procedure for grandfather upwards. But if the uncle's color is black then rotations in 4 possible ways are conducted untill one can recolour the new arrangement of the nodes.
What is Recursion?
Recursion is defined as a process which calls itself directly or indirectly and the corresponding function is called a recursive function. As an example calculation of Fibonacci series can be formulated in the form of Recursion, like F(n) = F(n-1) + F(n-2), for n >= 2.
What is Dynamic Programming?
Dynamic Programming is a method used in mathematics and computer science to solve complex problems by breaking them down into simpler subproblems. By solving each subproblem only once and storing the results, it avoids redundant computations, leading to more efficient solutions for a wide range of problems.
What is Linear Programming?
Linear programming is the technique used for optimizing a particular scenario. Using linear programming provides us with the best possible outcome in a given situation. It uses all the available resources in a manner such that they produce the optimum result. Problems like Transportation, manufacturing and diet can be solved by this approach.
A linear programming problem consits of Decision Variables, Objective Function, Constraints and Non-negative Restrictions. Decision variables are the variables x, and y, which decide the output of the linear programming problem and represent the final solution. The objective function, generally represented by Z, is the linear function that needs to be optimized according to the given condition to get the final solution. The restrictions imposed on decision variables that limit their values are called constraints. Now, the general formula of a linear programming problem is:
Objective Function: Z = ax + by
Constraints: cx + dy ≥ e, px + qy ≤ r
Non-Negative restrictions: x ≥ 0, y ≥ 0
The methods of solving linear programming problems are Simplex and Graphical.
Steps for the Simplex Method are:
Step 1: Formulate the linear programming problems based on the given constraints.
Step 2: Convert all the given inequalities to equations or equalities of the linear programming problems by adding the slack variable to each inequality where ever required.
Step 3: Construct the initial simplex table. By representing each constraint equation in a row and writing the objective function at the bottom row. The table so obtained is called the Simplex table.
Step 4: Identify the greatest negative entry in the bottom row the column of the element with the highest negative entry is called the pivot column
Step 5: Divide the entries of the right-most column with the entries of the respective pivot column, excluding the entries of the bottommost row. Now the row containing the least entry is called the pivot row. The pivot element is obtained by the intersection of the pivot row and the pivot column.
Step 6: Using matrix operation and with the help of the pivot element make all the entries in the pivot column to be zero.
Step 7: Check for the non-negative entries in the bottommost row if there are no negative entries in the bottom row, end the process else start the process again from step 4.
Step 8: The final simplex table so obtained gives the solution to our problem.
Steps for the Graphical Method are:
Step 1: First convert the inequations into normal equations.
Step 2: Find the points at which equations cut the x-axis and y-axis. To find the point of intersection of the x-axis put y = 0 in the respective equation and find the point. Similarly for y-axis intersection points put x = 0 in the respective equation.
Step 3: Draw the lines cutting the x-axis and y-axis.
Step 4: The region will include an area region enclosed by two axes and all lines including the origin.
Step 5: Find Z for each intersection point and thus maxima and minima.
What is Backtracking?
Backtracking is a problem-solving algorithmic technique that involves finding a solution incrementally by trying different options and undoing them if they lead to a dead end. It is commonly used in situations where you need to explore multiple possibilities to solve a problem, like searching for a path in a maze or solving puzzles like Sudoku.
What is a Greedy Algorithm?
Greedy Algorithm is defined as a method for solving optimization problems by taking decisions that result in the most evident and immediate benefit irrespective of the final outcome. It works for cases where minimization or maximization leads to the required solution.
Interview questions for C++.
Sources:
www.geeksforgeeks.org/cpp-interview-questions/
www.interviewbit.com/cpp-interview-questions/
www.simplilearn.com/tutorials/cpp-tutorial/cpp-interview-questions
www.linkedin.com/pulse/value-categories-c-amit-nadiger
www.scaler.com/topics/c/difference-between-if-else-and-switch/
learn.microsoft.com/en-us/cpp/cpp/smart-pointers-modern-cpp?view=msvc-170
www.learncpp.com/cpp-tutorial/circular-dependency-issues-with-stdshared_ptr-and-stdweak_ptr/
interviewprep.org/templates-programming-interview-questions/
www.studyplan.dev/pro-cpp/type-traits
www.linkedin.com/pulse/things-learn-c-template-metaprogramming-from-basic-advanced-dong
www.cppstories.com/2021/concepts-intro/?trk=article-ssr-frontend-pulse_little-text-block
github.com/mpavezb/cpp_concurrency?tab=readme-ov-file
en.cppreference.com/w/cpp/language/coroutines
medium.com/@litombeg/concurrency-in-c-passing-data-between-threads-promise-future-e22fb672736f
What is C++? What are the advantages of C++?
C++ is an object-oriented programming language that was introduced to overcome the jurisdictions where C was lacking. By object-oriented we mean that it works with the concept of polymorphism, inheritance, abstraction, encapsulation, object, and class.
Advantages of C++:
- C++ is an OOPs language that means the data is considered as objects.
- C++ is a multi-paradigm language; In simple terms, it means that we can program the logic, structure, and procedure of the program.
- Memory management is a key feature in C++ as it enables dynamic memory allocation.
- It is a Mid-Level programming language which means it can develop games, desktop applications, drivers, and kernels
What are the differences between C and C++?
| C | C++ |
| It is a procedural programming language. In simple words, it does not support classes and objects | It is a mixture of both procedural and object-oriented programming languages. In simple words, it supports classes and objects. |
| It does not support any OOPs concepts like polymorphism, data abstraction, encapsulation, classes, and objects. | It supports all concepts of data |
| It does not support Function and Operator Overloading | It supports Function and Operator Overloading respectively |
| It is a function-driven language | It is an object-driven language |
What are the different data types present in C++?
- Primary
- Integer
- Character
- Boolean
- Floating Point
- Double Floating Point
- Void
- Wide Character
- Derived
- Function
- Array
- Pointer
- Reference
- User Defined
- Class
- Structure
- Union
- Enum
- Typedef
Define ‘std’?
‘std’ is also known as Standard or it can be interpreted as a namespace. The command “using namespace std” informs the compiler to add everything under the std namespace and inculcate them in the global namespace. This all inculcation of global namespace benefits us to use “cout” and “cin” without using “std::operator”.
What is a Pointer in C++?
A Pointer is a variable that stores the memory address of an object. Pointers are used extensively in both C and C++ for three main purposes:
- To allocate new objects on the heap.
- To pass functions to other functions.
- To iterate over elements in arrays or other data structures.
What are references in C++?
When a variable is described as a reference it becomes an alias of the already existing variable. In simple terms, a referenced variable is another named variable of an existing variable keeping in mind that changes made in the reference variable will be reflected in the already existing variable. A reference variable is preceded with a ‘&’ symbol.
What are the differences between References and Pointers?
- You cannot have NULL references. You must always be able to assume that a reference is connected to a legitimate piece of storage.
- Once a reference is initialized to an object, it cannot be changed to refer to another object. Pointers can be pointed to another object at any time.
- A reference must be initialized when it is created. Pointers can be initialized at any time.
- To access the members of class/struct it uses a References use '.' and Pointers '->'.
What is meant by Call by Value and Call by Reference?
| Call by Value | Call by Reference |
| A copy of a variable is passed. | A variable itself is passed fundamentally. |
| Calling a function by sending the values by copying variables. | Calling a function by sending the address of the passed variable. |
| The changes made in the function are never reflected outside the function on the variable. In short, the original value is never altered in Call by Value. | The changes made in the functions can be seen outside the function on the passed function. In short, the original value is altered in Call by reference. |
| Passed actual and formal parameters are stored in different memory locations. Therefore, making Call by Value a little memory insufficient. | Passed actual and formal parameters are stored in the same memory location. Therefore, making Call by Reference a little more memory efficient. |
Define token in C++.
A token is the smallest individual element of a program that is understood by a compiler. A token comprises the following:
- Keywords – That contain a special meaning to the compiler
- Identifiers – That hold a unique value/identity
- Constants – That never change their value throughout the program
- Strings – That contains the homogenous sequence of data
- Special Symbols – They have some special meaning and cannot be used for another purpose; eg: [] () {}, ; * = #
- Operators – Who perform operations on the operand
What are the differences between Structures and Classes?
| Structures | Classes |
| Members of the struct are always by default public mode | Members of the class can be in private, protected, and public modes. |
| Structures are of the value type. They only hold value in memory. | Classes are of reference type. It holds a reference of an object in memory. |
| The memory in structures is stored as stacks. | The memory in classes is stored as heaps. |
Discuss prefix and postfix operators.
In the prefix version (i.e., ++i), the value of i is incremented, and the value of the expression is the new value of i. Prefix operator returns the reference to the incremented variable. In the postfix version (i.e., i++), the value of i is incremented, but the value of the expression is the original value of i.
What is the difference between new and malloc()?
| new | malloc() |
| new is an operator which performs an operation | malloc is a function that returns and accepts values |
| new calls the constructors | malloc cannot call a constructor |
| new is faster than malloc as it is an operator | malloc is slower than new as it is a function |
| new returns the exact data type | malloc returns void* |
What are the differences between Program Stack and Heap memory types?
- Stack is a linear data structure whereas Heap is a hierarchical data structure.
- Stack memory will never become fragmented whereas Heap memory can become fragmented as blocks of memory are first allocated and then freed.
- Stack accesses local variables only while Heap allows you to access variables globally.
- Stack variables can’t be resized whereas Heap variables can be resized.
- Stack memory is allocated in a contiguous block whereas Heap memory is allocated in any random order.
- Stack doesn’t require to de-allocate variables whereas in Heap de-allocation is needed.
- Stack allocation and deallocation are done by compiler instructions whereas Heap allocation and deallocation is done by the programmer.
What is the difference between function overloading and operator overloading?
| Function Overloading | Operator Overloading |
| It is basically defining a function in numerous ways such that there are many ways to call it or in simple terms you have multiple versions of the same function | It is basically giving practice of giving a special meaning to the existing meaning of an operator or in simple terms redefining the pre-redefined meaning |
| Parameterized Functions are a good example of Function Overloading as just by changing the argument or parameter of a function you make it useful for different purposes | Polymorphism is a good example of an operator overloading as an object of allocations class can be used and called by different classes for different purposes |
| Example of Function Overloading: int GFG(int X, int Y); int GFG(char X, char Y); | Example of Operator Overloading: int GFG() = X() + Y(); int GFG() = X() – Y(); |
What does the Scope Resolution operator do?
A scope resolution operator is denoted by a ‘::‘ symbol. Just like its name this operator resolves the barrier of scope in a program. A scope resolution operator is used to reference a member function or a global variable out of their scope furthermore to which it can also access the concealed variable or function in a program.
Scope Resolution is used for numerous amounts of tasks:
- To access a global variable when there is a local variable with the same name.
- To define the function outside the class.
- In case of multiple inheritances.
- For namespace.
What is the difference between shallow copy and deep copy?
| Shallow Copy | Deep Copy |
| Shallow Copy stores the references of objects to the original memory address. | Deep copy stores copies of the object’s value. |
| Shallow Copy reflects changes made to the new/copied object in the original object. | Deep copy doesn’t reflect changes made to the new/copied object in the original object. |
| Shallow Copy stores the copy of the original object and points the references to the objects. | Deep copy stores the copy of the original object and recursively copies the objects as well. |
| A shallow copy is faster. | Deep copy is comparatively slower. |
Can you compile a program without the main function?
Yes, it is absolutely possible to compile a program without a main(). For example Use Macros that defines the main.
#include <iostream>
#define fun main
int fun(void)
{
std::cout << "Compiling without main()" << std::endl;
return 0;
}
Using Token-Pasting Operator:
#include <iostream>
#define fun m##a##i##n
int fun()
{
std::cout << "Compiling without main()" << std::endl;
return 0;
}
Using Argumented Macro:
#include <iostream>
#define begin(m,a,i,n) m##a##i##n
#define start begin(m,a,i,n)
int fun()
{
std::cout << "Compiling without main()" << std::endl;
return 0;
}
Define inline function. Can we have a recursive inline function in C++?
An inline function cannot be recursive because in the case of an inline function the code is merely placed into the position from where it is called and does not maintain a piece of information on the stack which is necessary for recursion.
Plus, if you write an inline keyword in front of a recursive function, the compiler will automatically ignore it because the inline is only taken as a suggestion by the compiler.
Define the spicifier 'auto'.
The 'auto' keyword in C++ automatically detects and assigns a data type to the variable with which it is used. The compiler analyses the variable's data type by looking at its initialization.
auto integerNumber = 20;
auto floatNumber = 1.2;
auto sum(const int& integerNumber, const float& floatNumber2)
{
return (integerNumber+floatNumber);
}
Define the specifier 'decltype'.
The decltype type specifier yields the type of a specified expression. The decltype type specifier, together with the auto keyword, is useful primarily to developers who write template libraries.
struct A { double x; };
const A* a;
decltype(a->x) y; // type of y is double (declared type)
decltype((a->x)) z = y; // type of z is const double& (lvalue expression)
template<typename T, typename U>
auto add(T t, U u) -> decltype(t + u) // return type depends on template parameters. Return type can be deduced since C++14
{
return t + u;
}
Define the specifier 'constexpr'.
The 'constexpr' specifier declares that it is possible to evaluate the value of the function or variable at compile time. Such variables and functions can then be used where only compile time constant expressions are allowed (e.g. template meta-programming).
What is the main use of the keyword 'volatile'?
It is used to inform the compiler that the value may change anytime. Also, the volatile keyword prevents the compiler from performing optimization on the code. It was intended to be used when interfacing with memory-mapped hardware, signal handlers, and machine code instruction.
Define storage class in C++ and name some.
Storage class is used to define the features(lifetime and visibility) of a variable or function. These features usually help in tracing the existence of a variable during the runtime of a program.
- auto - type of a variable is defined automatically after initialization.
- register - has the same functionality as that of the auto variables, the only difference is that the compiler tries to store these variables in the register of the microprocessor if a free register is available. This makes the use of register variables to be much faster than that of the variables stored in the memory during the runtime of the program. If a free register is not available, these are then stored in the memory only. An important and interesting point to be noted here is that we cannot obtain the address of a register variable using pointers.
- extern - tells us that the variable is defined elsewhere and not within the same block where it is used.
- static - static variables have the property of preserving their value even after they are out of their scope. One can say that they are initialized only once and exist until the termination of the program.
- mutable - the keyword mutable is mainly used to allow a particular data member of a const object to be modified.
- thread_local - allows each thread in a multi-threaded program to have its own separate instance of a variable.
Enlist Value Categories.
- A glvalue (“generalized” lvalue) is an expression whose evaluation determines the identity of an object or function. It includes both lvalues and certain rvalues. Examples of glvalues include variables, references, and functions.
Characteristics:
- Can have an identifiable memory address.
- Can be used on the left-hand side of an assignment.
- Can have their address taken using the "&" operator.
- Have a lifetime that extends beyond the current expression.
Advantages:
- Can be used as both lvalues and rvalues, providing flexibility in expression usage.
- Allows modifying the value it refers to.
Disadvantages:
- Requires identifiable memory addresses, which may limit certain optimizations.
Usecases:
- Passing arguments to functions by reference.
- Assigning values to variables.
- Using objects as operands in expressions.
Examples:int x = 10; int& ref = x; //As an lvalue // assigning a new value x = 20; ref = 30; // taking the adress int* ptr = &x; int* ptr = &ref; // As an rvalue // using in an expression int sum = x + 5; int sum = ref + 5; // Passing to a function expecting an rvalue void printValue(int value){}; printValue(x); printValue(ref); - An lvalue is a subset of glvalue and represents an object or function that has a persistent identity. It refers to a specific memory location and can be used to retrieve or modify the value stored at that location. Examples of lvalues include variables and named objects.
Characteristics:
- Has an identifiable memory address.
- Can be assigned a value.
- Can be used on the left-hand side of an assignment.
- Can have their address taken.
Advantages:
- Provides a reference to an existing object, allowing direct modification.
- Enables aliasing and referencing of objects.
Disadvantages:
- May introduce aliasing issues if not used carefully.
- Cannot be bound to rvalue references.
Usecases:
- Assigning values to variables.
- Passing arguments or values to functions by reference.
- Accessing and modifying object properties.
Examples:int x = 10; int& ref = x; // assigning a new value x = 20; ref = 30; // taking the adress int* ptr = &x; int* ptr = &ref; // Passing to a function by reference void printValue(int& value){}; printValue(x); printValue(ref); - A prvalue (pure rvalue) represents a temporary or literal value. It does not have an identifiable memory address and is typically used as a source for initialization or computation. Examples of prvalues include literals, temporary objects, and expressions that generate a value directly.
Characteristics:
- Cannot have their address taken.
- Can be implicitly converted to rvalues.
- Often used in initializations and computations.
Advantages:
- Efficient for temporary values that don't need to be modified.
- Can be moved instead of copied, improving performance.
Disadvantages:
- Cannot be modified directly.
- Does not have an identifiable memory address.
Usecases:
- Initializing variables with literals or temporary objects.
- Creating temporary objects.
- Calculating intermediate values in expressions.
- Performing arithmetic or logical operations.
Examples:int result = 2 + 3; // here the expression '2+3' is a prvalue - An xvalue (eXpiring Values) represents a value that is about to expire, typically because it is bound to a soon-to-be-destroyed object. It is a subset of rvalues and is used to enable efficient resource management through move semantics. Examples of xvalues include the result of std::move() or a cast to an rvalue reference.
Characteristics:
- Represents a value that can be moved from.
- Typically used in move operations or transferring ownership.
- Can be used to efficiently transfer resources.
Advantages:
- Allows the transfer of resources from one object to another, improving efficiency.
- Enables move semantics for better performance.
Disadvantages:
- Requires careful handling to avoid using an expired or invalidated object.
Usecases:
- Implementing move constructors and move assignments operator.
- Transferring ownership of resources between objects.
Examples:#include <iostream> #include <string> std::string createString() { return "Hello, World!"; } int main() { std::string&& x = createString(); // x is an xvalue std::cout << x << std::endl; // Accessing x before it expires return 0; } - An rvalue represents a temporary or disposable value that does not have a persistent identity. It is typically used as a source of data or a target for move operations. Examples of rvalues include literals, temporary objects, and the result of certain expressions.
Characteristics:
- Typically short-lived and disposable.
- Cannot be used on the left-hand side of an assignment.
- Can be moved from or copied.
Advantages:
- Allows efficient use of temporary values.
- Enables move semantics for better performance.
Disadvantages:
- Cannot be modified directly.
- Does not have an identifiable memory address.
Usecases:
- Initializing variables with literals or temporary objects.
- Passing arguments to functions by value.
- Returning values from functions by value.
- Using temporary values in expressions.
Examples:int result = getX() + getY(); // the expression getX() + getY() is an rvalue
Explain 'move()' semantics.
It was designed to move objects, whose lifetime expires, instead of copying them. The data is transferred from one object to another. In most cases, the data transfer does not move this data physically in memory.
#include <iomanip>
#include <iostream>
#include <string>
#include <utility>
#include <vector>
int main()
{
std::string str = "Salut";
std::vector<std::string> v;
// uses the push_back(const T&) overload, which means
// we'll incur the cost of copying str
v.push_back(str);
std::cout << "After copy, str is " << std::quoted(str) << '\n';
// uses the rvalue reference push_back(T&&) overload,
// which means no strings will be copied; instead, the contents
// of str will be moved into the vector. This is less
// expensive, but also means str might now be empty.
v.push_back(std::move(str));
std::cout << "After move, str is " << std::quoted(str) << '\n';
std::cout << "The contents of the vector are {" << std::quoted(v[0])
<< ", " << std::quoted(v[1]) << "}\n";
}
Explain Perfect Forwarding.
Perfect forwarding is there to ensure that the argument provided to a function is forwarded (passed) to another function with the same value category (basically r-value vs l-value) as originally provided. It is typically used with template functions where reference collapsing may have taken place.
#include <iostream>
#include <memory>
#include <utility>
struct A
{
A(int&& n) { std::cout << "rvalue overload, n=" << n << '\n'; }
A(int& n) { std::cout << "lvalue overload, n=" << n << '\n'; }
};
class B
{
public:
template<class T1, class T2, class T3>
B(T1&& t1, T2&& t2, T3&& t3) :
a1_{std::forward<T1>(t1)},
a2_{std::forward<T2>(t2)},
a3_{std::forward<T3>(t3)}
{}
private:
A a1_, a2_, a3_;
};
template<class T, class U>
std::unique_ptr<T> make_unique1(U&& u)
{
return std::unique_ptr<T>(new T(std::forward<U>(u)));
}
template<class T, class... U>
std::unique_ptr<T> make_unique2(U&&... u)
{
return std::unique_ptr<T>(new T(std::forward<U>(u)...));
}
auto make_B(auto&&... args) // since C++20
{
return B(std::forward<decltype(args)>(args)...);
}
int main()
{
auto p1 = make_unique1<A>(2); // rvalue
int i = 1;
auto p2 = make_unique1<A>(i); // lvalue
std::cout << "B\n";
auto t = make_unique2<B>(2, i, 3);
std::cout << "make_B\n";
[[maybe_unused]] B b = make_B(4, i, 5);
}
Output:
rvalue overload, n=2
lvalue overload, n=1
B
rvalue overload, n=2
lvalue overload, n=1
rvalue overload, n=3
make_B
rvalue overload, n=4
lvalue overload, n=1
rvalue overload, n=5
What are Range Based For Loops?
Range-based for loop in C++ has been added since C++ 11. It executes a for loop over a range. Used as a more readable equivalent to the traditional for loop operating over a range of values, such as all elements in a container.
#include <iostream>
#include <map>
#include <string>
#include <vector>
using namespace std;
// Driver
int main()
{
// Iterating over whole array
vector<int> v = { 0, 1, 2, 3, 4, 5 };
for (auto i : v)
cout << i << ' ';
cout << '\n';
// Iterating over whole array by reference
for (auto& i : v)
cout << i << ' ';
cout << '\n';
// the initializer may be a braced-init-list
for (int n : { 0, 1, 2, 3, 4, 5 })
cout << n << ' ';
cout << '\n';
// Iterating over array
int a[] = { 0, 1, 2, 3, 4, 5 };
for (int n : a)
cout << n << ' ';
cout << '\n';
// Just running a loop for every array
// element
for (int n : a)
cout << "In loop" << ' ';
cout << '\n';
// Printing string characters
string str = "Geeks";
for (char c : str)
cout << c << ' ';
cout << '\n';
// Printing keys and values of a map
map<int, int> MAP({ { 1, 1 }, { 2, 2 }, { 3, 3 } });
for (auto i : MAP)
cout << '{' << i.first << ", " << i.second << "}\n";
}
Enlist some key advantages of 'switch' over 'if-else' ladders.
- A switch statement is significantly faster than an if-else ladder if there are many nested if-else's involved. This is due to the creation of a jump table for switch during compilation. As a result, instead of checking which case is satisfied throughout execution, it just decides which case must be completed. The number of comparisons made is lesser hence, reducing the compile time. Hence, the switch would work better while selecting from a large set of values.
- When compared to if-else statements, it is more readable. You can also see this in the examples given below. In the if-else code, you can't clearly see the months which have 30 days; however, in switch, it's easily highlighted.
// Example of an if-else ladder
if (month == 'January' || month == 'March' || month == 'May' || month == 'July' || month == 'August' || month == 'October' || month == 'December') {
cout << '31';
} else if (month == 'February') {
cout << '28 or 29';
} else {
cout << '30';
}
// Example of the same logic implemented by switch construct
switch (month) {
case 1:
case 3:
case 5:
case 7:
case 8:
case 10:
case 12:
cout << "31";
break;
case 2:
cout << "28 or 29";
break;
case 4:
case 6:
case 9:
case 11:
cout << "30";
break;
default:
cout << "Not a valid month!";
break
}
Which operations are permitted on pointers?
Pointers are the variables that are used to store the address location of another variable. Operations that are permitted to a pointer are:
- Increment/Decrement of a Pointer.
- Addition and Subtraction of integer to a pointer.
- Comparison of pointers of the same type.
What are Smart Pointers? Enlist their types.
Smart pointers are defined in the std namespace in the memory.h header file. They are crucial to the RAII or Resource Acquisition Is Initialization programming idiom. The main principle of RAII is to give ownership of any heap-allocated resource—for example, dynamically-allocated memory or system object handles to a stack-allocated object whose destructor contains the code to delete or free the resource and also any associated cleanup code. A smart pointer is a class template that you declare on the stack, and initialize by using a raw pointer that points to a heap-allocated object. After the smart pointer is initialized, it owns the raw pointer. This means that the smart pointer is responsible for deleting the memory that the raw pointer specifies. The smart pointer destructor contains the call to delete, and because the smart pointer is declared on the stack, its destructor is invoked when the smart pointer goes out of scope, even if an exception is thrown somewhere further up the stack.
- unique_ptr - Allows exactly one owner of the underlying pointer. Can be moved to a new owner, but not copied or shared. This type of smart pointers is small and efficient; the size is one pointer and it supports rvalue references for fast insertion and retrieval from C++ Standard Library collections.
- shared_ptr - is a reference-counted smart pointer. Use when you want to assign one raw pointer to multiple owners, for example, when you return a copy of a pointer from a container but want to keep the original. The raw pointer is not deleted until all shared_ptr owners have gone out of scope or have otherwise given up ownership. The size is two pointers; one for the object and one for the shared control block that contains the reference count.
- weak_ptr - is a special-case smart pointer for use in conjunction with shared_ptr. A weak_ptr provides access to an object that is owned by one or more shared_ptr instances, but does not participate in reference counting and thus has no ownership of the object. Use when you want to observe an object, but do not require it to remain alive. Required in some cases to break circular references, which can cause memory leaks in structures such as doubly-linked lists or graphs where two objects reference each other using std::shared_ptr. A weak pointer can be created only from a shared pointer.
Give an example of Circular Dependency issues with std::shared_ptr, and how to resolve it with std::weak_ptr.
Consider the following case, where the shared pointers in two separate objects each point at the other object:
#include <iostream>
#include <memory> // for std::shared_ptr
#include <string>
class Person
{
std::string m_name;
std::shared_ptr<Person> m_partner; // initially created empty
public:
Person(const std::string &name): m_name(name)
{
std::cout << m_name << " created\n";
}
~Person()
{
std::cout << m_name << " destroyed\n";
}
friend bool partnerUp(std::shared_ptr<Person> &p1, std::shared_ptr<Person> &p2)
{
if (!p1 || !p2)
return false;
p1->m_partner = p2;
p2->m_partner = p1;
std::cout << p1->m_name << " is now partnered with " << p2->m_name << '\n';
return true;
}
};
int main()
{
auto lucy { std::make_shared<Person>("Lucy") }; // create a Person named "Lucy"
auto ricky { std::make_shared<Person>("Ricky") }; // create a Person named "Ricky"
partnerUp(lucy, ricky); // Make "Lucy" point to "Ricky" and vice-versa
return 0;
}
Output: Lucy created Ricky createdLucy is now partnered with Ricky
No deallocations took place. It happend because while calling the distructor of ricky object there was still another pointer to ricky in lucy object and vice versa. This situation can even happen with a single object pointing to itself. In order to solve the problem for the example given above, let's change the type of m_partner from shared_ptr to weak_ptr.
Output: Lucy created Ricky created Lucy is now partnered with Ricky Ricky destroyed Lucy destroyed
Are Shared Pointers thread safe?
Only the reference counting part of the shared_ptr is atomic and thus thread safe. The shared_ptr itself is not thread safe.
- Different std::shared_ptr instances can be read from and modified by multiple threads at the same time, even if these instances are copies and share ownership of the same object.
- The same std::shared_ptr instance can be read by multiple threads simultaneously.
- The same std::shared_ptr instance cannot be directly modified by multiple threads without additional synchronization. But can be done by means of mutex and atomics.
What are the various OOPs concepts in C++?
- Classes: It is a user-defined datatype
- Objects: It is an instance of a class
- Abstraction: It is a technique of showing only necessary details
- Encapsulation: Wrapping of data in a single unit
- Inheritance: The capability of a class to derive properties and characteristics from another class
- Polymorphism: Polymorphism is known as many forms of the same thing
What are Classes and Objects in C++?
A class is a user-defined data type where all the member functions and data members are tailor-made according to demands and requirements in addition to which these all can be accessed with the help of an object. To declare a user-defined data type we use a keyword class.
An object is an instance of a class and an entity with value and state; In simple terms, it is used as a catalyst or to represent a class member. It may contain different parameters or none.
What are the C++ access modifiers?
The access restriction specified to the class members( whether it is member function or data member) is known as access modifiers/specifiers.
Access Modifiers are of 3 types:
- private – It can neither be accessed nor be viewed from outside the class.
- protected – It can be accessed if and only if the accessor is the derived class.
- public – It can be accessed or be viewed from outside the class.
What is the difference between 'struct' and 'class'?
The two constructs are identical in C++ except that in structs the default accessibility is public, whereas in classes the default is private. One can even use inheritence for structures, but the acessibility by default is public.
What is the difference between C and C++ structures?
C++ structures can have not only data members, but also functions. The C++ structures can have inheritance as well, what is not possible for C structures.
What is an Abstract Class and when do you use it?
An abstract class is a class that is specifically designed to be used as a base class. An abstract class contains at least one pure virtual function. You declare a pure virtual function by using a pure specifier (= 0) in the declaration of a virtual member function in the class declaration.
You cannot use an abstract class as a parameter type, a function return type, or the type of an explicit conversion, nor can you declare an object of an abstract class. However, it can be used to declare pointers and references to an abstract class.
An abstract class is used if you want to provide a common, implemented functionality among all the implementations of the component. Abstract classes will allow you to partially implement your class, whereas interfaces would have no implementation for any members whatsoever. In simple words, Abstract Classes are a good fit if you want to provide implementation details to your children but don’t want to allow an instance of your class to be directly instantiated.
What are the static data members and static member functions?
Static data member in C++ are declared inside the class but they are initialized outside of the class. Static member functions can be accessed using class name and scope resolution operator. Also, we can call the static member function without creating any object of the class.
Explain inheritance.
The capability or ability of a class to derive properties and characteristics from another class is known as inheritance. In simple terms, it is a system or technique of reusing and extending existing classes without modifying them.
When should we use multiple inheritance?
Multiple inheritances mean that a derived class can inherit two or more base/parent classes. It is useful when a derived class needs to combine numerous attributes/contracts and inherit some, or all, of the implementation from these attributes/contracts.
What is virtual inheritance?
Virtual inheritance is a technique that ensures only one copy of a base class’s member variables is inherited by grandchild-derived classes. Or in simple terms, virtual inheritance is used when we are dealing with a situation of multiple inheritances but want to prevent multiple instances of the same class from appearing in the inheritance hierarchy.
#include <iostream>
using namespace std;
class A {
public:
void show()
{
cout << "Hello form A \n";
}
};
class B : public A {
};
class C : public A {
};
class D : public B, public C {
};
int main()
{
D object;
object.show();
}
Output:error: request for member 'show' is ambiguous object.show();
As we can see from above, data members/function of class A are inherited twice to class D. One through class B and second through class C. When any data / function member of class A is accessed by an object of class D, ambiguity arises as to which data/function member would be called? One inherited through B or the other inherited through C. This confuses compiler and it displays error.
One can resolve it by virtual inheritence:
#include <iostream>
using namespace std;
class A {
public:
void show()
{
cout << "Hello form A \n";
}
};
class B : public virtual A {
};
class C : public virtual A {
};
class D : public B, public C {
};
int main()
{
D object;
object.show();
}
Output:Hello from A
Now class B and class C use the virtual base class A and no duplication of member function is done; Classes B and C share a single copy of the members in the virtual base class A.
What is polymorphism in C++?
Polymorphism is known as many forms of the same thing. In simple terms, we can say that Polymorphism is the ability to display a member function in multiple forms depending on the type of object that calls it. There is 2 type of polymorphism:
Compile Time Polymorphism or Static Binding:
- Function Overloading
- Operator Overloading
Run Time Polymorphism or Late Binding:
- Function Overriding
- Virtual Function
What is Function Overriding?
When a function of the same name, same arguments or parameters, and same return type already present/declared in the base class is used in a derived class is known as Function Overriding. It is an example of Runtime Polymorphism or Late Binding which means the overridden function will be executed at the run time.
What is the difference between Virtual Functions and Pure Virtual Functions?
A Virtual Function is a member function of a base class which can be redefined by derived class. A Pure Virtual Function is a member function of a base class only with a declaration provided in the base class and it should be defined in a derived class otherwise derived class also becomes abstract.
Explain Constructors in C++.
A constructor is a special type of member function of a class, whose name is the same as that of the class by whom it is invoked. It initializes value to the object of a class.
There are 4 types of constructors:
- Default constructor: It is the most basic type of constructor which accepts no arguments or parameters. Even if it is not called the compiler calls it automatically when an object is created.
- Parameterized constructor: It is a type of constructor which accepts arguments or parameters. It has to be called explicitly by passing values in the arguments as these arguments help initialize an object when it is created. It also has the same name as that of the class.
- Copy Constructor: A copy constructor is a member function that initializes an object using another object of the same class. Also, the Copy constructor takes a reference to an object of the same class as an argument.
- Move Constructore: A move constructor is a special member function that moves ownership of an existing object's data to a new variable without copying the original data.
What is the sequence of calling Constructors in a Class Hierarhcy?
A constructor performs its work in this order:
- It calls base class and member constructors in the order of declaration.
- If the class is derived from virtual base classes, it initializes the object's virtual base pointers.
- If the class has or inherits virtual functions, it initializes the object's virtual function pointers. Virtual function pointers point to the class's virtual function table to enable correct binding of virtual function calls to code.
- It executes any code in its function body.
Explain Destructors in C++.
Destructors are member functions in a class that delete an object when an object of the class goes out of scope. Destructors have the same name as the class preceded by a tilde (~) sign. Also, destructors follow a down-to-top approach, unlike constructors which follow a top-to-down.
When is a Destructor in a Base Class should be virtual?
When destroying instances or objects of a derived class using a base class pointer object, a virtual destructor is invoked to free up memory space allocated by the derived class object or instance.
Virtual destructor guarantees that first the derived class’ destructor is called. Then the base class’s destructor is called to release the space occupied by both destructors in the inheritance class which saves us from the memory leak. It is advised to make your destructor virtual whenever your class is polymorphic.
Is Destructor Overloading possible?
The simple answer is no we cannot overload a destructor. It is mandatory to have only one destructor per class in C++.
Can a Destructor have parameters?
Destructors neither take any arguments nor they have a parameter that might help to overload.
What is a Template in programming and why it is useful?
A template in programming is a tool that allows developers to write generic code, making it reusable and adaptable for any types and classes.
What is the difference between a Template Function and Function Overloading in C++?
You use the function overloading when you want to perform similar operations. On the other hand, templates in C++ are used to perform precisely identical operations on different data types. A good indicator to choose between these two techniques is to verify that no Code Duplication is generated.
How does Template Specialization in C++ work?
Template specialization in C++ allows for different code to be executed depending on the data type used. It’s a way of customizing template classes or functions for specific types or values, enhancing flexibility and efficiency.
Consider a simple template function that returns the larger of two inputs:
template <typename T>
T max(T a, T b) {
return (a > b)? a : b;
}
We can specialize it for char* type where it compares strings lexicographically instead:
template <>
const char* max<const char*>(const char* a, const char* b) {
return (strcmp(a, b) > 0)? a : b;
}
What is a Class Template in C++ and how is it different from Function Templates?
A class template in C++ is a blueprint for creating generic classes. It allows the same class to accommodate different data types without rewriting code, enhancing reusability and efficiency. A function template creates a family of functions with different argument types.
Explain how template metaprogramming works.
Template metaprogramming (TMP) is a technique in C++ where templates are used to perform compile-time computations. TMP leverages the compiler’s ability to interpret template parameters as types or values, enabling computation at compile time rather than runtime. This results in more efficient code execution.
In TMP, templates act as both containers of generic algorithms and generators of specific implementations for different data types. The process begins when a programmer defines a template with one or more parameters. During compilation, the compiler generates an appropriate function or class based on the provided arguments.
A key feature of TMP is its recursive nature. A template can call itself with modified parameters until a base case is reached. This recursion happens during compilation, not execution, leading to highly optimized code.
However, TMP has drawbacks such as increased complexity and longer compile times. It also requires deep understanding of C++ syntax and semantics. Despite these challenges, it remains a powerful tool for optimizing performance-critical applications.
Can you discuss some of the potential problems or challenges that can occur when working with templates?
Templates, while powerful tools in programming, can present several challenges.
- One common issue is Code Bloat, where each template instantiation generates a new set of functions or classes, leading to increased binary size. This can also cause longer compilation times.
- Another problem is Debugging Difficulty due to complex error messages. Templates are instantiated at compile-time and any errors that occur during this process result in verbose and often confusing compiler diagnostics.
- Type Checking Issues may arise as well. Since templates work with generic types, it’s possible for the programmer to use an inappropriate type, causing unexpected behavior or runtime errors.
- Lastly, there’s the risk of Poor Abstraction. If not used carefully, templates can lead to tightly coupled code, reducing modularity and making maintenance more difficult.
Enlist Types of Template Parameters.
There are 3 basic types of template parameters:
- Type Parameters.
- Non-type Parameters.
- Template-template Parameters.
Examples for them are:
template<class T, std::size_t N> // T is a type parameter and N is non-type parameter.
struct array;
std::array<int, 5> arr = {1, 2, 3, 4, 5}; // example of initialization.
template<class T, class Container = std::deque<T>> // Container is a template-template parameter.
class stack;
Explain the difference between Template Classes and Class Templates.
Template classes and class templates, while sounding similar, serve different purposes in programming. A class template is a blueprint for creating classes. It allows the programmer to define generic types, making it possible to create a class that can work with different data types. For instance, you could have a class template for an array that works with integers, floats, or any other type.
On the other hand, a template class is a specific instance of a class template. When we instantiate a class template with a particular data type, we get a template class. Using our previous example, if we use our array class template to create an array of integers, the resulting class is a template class.
How can you create a templated function within a class in C++?
To create a templated function within a class in C++, you first declare the template above your class. This is done using the ‘template’ keyword followed by ‘T‘ where T is a placeholder for any data type. Inside the class, you can then define your function as usual but use T instead of a specific data type.
template <typename T>
class MyClass {
public:
T myFunction(T param) {
// Function body here
}
};
Can you explain the term Template Instantiation?
Template instantiation in programming refers to the process of creating a specific function or class from a template. This is done by the compiler, which replaces the generic types in the template with the specified types provided by the programmer.
What is meant by Template Argument Deduction in C++?
Template argument deduction in C++ is a compiler process that determines the types of template arguments from function or class template calls. It allows developers to omit explicit template arguments while calling these templates, enhancing code readability and maintainability. The compiler deduces the type based on the provided arguments. For instance, if we have a function template ‘void func(T arg)’ and call it as ‘func(5)’, the compiler deduces T as int. However, this process has limitations. If the deduction leads to ambiguity or no valid match, it fails, causing a compile-time error.
Can you explain the difference between Complete and Incomplete Template Specialization?
Complete template specialization refers to the process where all template parameters are provided, resulting in a specific type or function. This allows for unique behavior when certain types are used as arguments.
On the other hand, incomplete (or partial) template specialization involves specifying some but not all template parameters. It’s useful when we want to define different behaviors for a subset of types, while still maintaining general behavior for others.
#include <iostream>
using namespace std;
// Primary template
template <typename T, typename X>
class Person {
public:
void Print() { cout << "Primary Template" << endl; }
};
// Partial specialization for X as int
template <typename T> class
Person<T, int> {
public:
void Print()
{
cout << "Partial Specialization for int" << endl;
}
};
// driver code
int main()
{
Person<bool, double> person1;
Person<bool, int> person2;
person1.Print();
person2.Print();
return 0;
}
What are Variadic Templates in C++ and how are they useful?
Variadic templates in C++, introduced in C++11, allow a function or class to accept an indefinite number of arguments. This is achieved by using the ellipsis operator (…) in template parameters. They are useful for creating generic functions or classes that can handle any number and type of arguments, enhancing code reusability and efficiency.
For instance, consider a simple print function. Without variadic templates, we would need separate versions for different argument counts/types. With variadic templates, one version suffices:
template<typename... Args>
void print(Args... args) {
(std::cout << ... << args);
}
Can you discuss a situation when it would be more beneficial to use a virtual function rather than a template?
In object-oriented programming, a situation where it would be more beneficial to use a virtual function rather than a template is when dealing with dynamic polymorphism. Dynamic polymorphism allows objects of different types to be treated at run-time as objects of a common parent type. This is useful in scenarios where we have an array or list of objects of the base class type but each needs to execute their version of a function.
Templates wouldn’t work here because they’re resolved at compile-time, while virtual functions are dynamically bound at runtime. Thus, templates can’t provide the dynamic dispatch needed for this kind of polymorphism.
How can you prevent the instantiation of a template for a particular data type?
To prevent the instantiation of a template for a specific data type, you can use explicit specialization or SFINAE (Substitution Failure Is Not An Error). Explicit specialization allows you to define a different implementation for a particular data type. If this specialized version is not suitable for the given arguments, it won’t be used and will result in a compile error. SFINAE technique involves creating a condition that causes substitution failure if a certain type is used. This can be achieved using std::enable_if or similar meta-programming techniques. For instance:
template <class T , typename = std::enable_if <!std::is_same<T,Foo>::value,T>::type >
class MyClass{
//...
};
Explain the potential challenges of debugging a templated code and how would you overcome them?
Debugging templated code can be challenging due to Type Independence, Compiler Errors, and Instantiation Issues.
Type Independence means that a template function or class works with any data type. This flexibility can lead to unexpected behavior if the types used don’t support all operations in the template.
Compiler Errors are another challenge. They often become complex and difficult to understand when templates are involved because compilers generate them based on instantiated templates, not the template definition itself.
Lastly, debugging is complicated by the fact that templates aren’t fully instantiated until they’re used. Errors may only appear at this point, making it hard to isolate their source.
To overcome these challenges, use static assertions to enforce type requirements. This helps catch errors early and provides clearer messages than those generated by the compiler. Also, consider using concept checks (if your language supports them) to specify what operations a type must support to be used with a particular template.
When dealing with compiler errors, try instantiating the problematic template with a specific type. This can make error messages more understandable.
Finally, for instantiation issues, ensure you thoroughly test each template with various types.
What are Template Type Traits in C++?
Type traits are a feature of C++ that allows performing compile-time analysis of types. Common use cases of type traits are:
- Template type safety and documentation: ensuring that template functions are only called with the expected types, thereby preventing runtime errors, and improving the developer experience.
- Compile-Time if statements: enabling or disabling lines of code based on the properties of a type, or other compile-time factors.
- Template metaprogramming: writing code to change how templates are generated and used at compile time.
- Conditional type selection: changing the data types we use based on boolean expressions.
- Custom types: how our own user-defined types can interact with any of these systems. For example, the std::is_arithmetic type trait tells us if a type is numeric:
#include <type_traits>
#include <iostream>
int main() {
if (std::is_arithmetic<int>::value) {
std::cout << "int is arithmetic";
}
if (!std::is_arithmetic<std::string>::value) {
std::cout << "\n but std::string isn't";
}
}
Some more examples of type traits:
- std::is_pointer lets us determine if a type is a pointer.
- std::is_class lets us determine if a type is a class or struct, excluding enums and unions.
- std::is_same lets us determine if a type is the same as another type.
- std::is_base_of lets us determine if a type is the same as another type, or derived from that type through inheritance.
How to check a Trait at Compile-Time in a Template?
By using if constexpr statements. These are evaluated at compile time and, if the expression we pass to if constexpr evaluates to false, the block of code is removed from our function entirely.
#include <iostream>
#include <type_traits>
template <typename T>
void LogDouble(T Param) {
if constexpr (std::is_arithmetic_v<T>) {
std::cout << "Double: " << Param * 2;
}
}
int main() {
LogDouble(42);
LogDouble(std::string("Hello World"));
}
The instantiated functions from above look like this:
void LogDouble(int Param) {
std::cout << "Double: " << Param * 2;
}
void LogDouble(std::string Param) {}
String type has no operator '*'.
Define a Metafunction.
A metafunction is not a function but a class/struct. But like regular functions, it can also 'return' something, such as a value or a type. See the following examples:
// Return a value from a metafunction
template <int NUM>
struct PlusOne
{
static constexpr int value = NUM + 1;
};
PlusOne<1>::value; // returns 2
// Return a type from a metafunction
template <typename T>
struct Echo
{
using type = T; // returns type
};
constexpr Echo<int>::type i = 5;
What is a Concept for Templates?
A concept is a set of constraints on template parameters evaluated at compile time. They can be use for class templates and function templates to control function overloads and partial specialization.
C++20 gives a language support (new keywords - requires, concept) and a set of predefined concepts from the Standard Library. Here are some examples:
// a simple concept called integral
template <class T>
concept integral = std::is_integral_v<T>;
/*
We defined a concept that requires that an object of type T has a member function called buildHtml(),
which returns something convertible to std::string.
*/
template <typename T>
concept ILabel = requires(T v)
{
{v.buildHtml()} -> std::convertible_to<std::string>;
};
And another more complex example:
#include <numeric>
#include <vector>
#include <iostream>
#include <concepts>
template <typename T>
requires std::integral<T> || std::floating_point<T>
constexpr double Average(std::vector<T> const &vec) {
const double sum = std::accumulate(vec.begin(), vec.end(), 0.0);
return sum / vec.size();
}
int main() {
std::vector ints { 1, 2, 3, 4, 5};
std::cout << Average(ints) << '\n';
}
What is the main advantage of Concepts?
The main advantage is more readable and understandable compiler errors.
What is C++ STL?
The Standard Template Library (STL) is a set of C++ template classes to provide common programming data structures and functions such as lists, stacks, arrays, etc. It is a generalized library and so, its components are parameterized.
STL has 4 components:
- Containers
- Iterators
- Algorithms
- Functors
Enlist Container Types in STL.
- Sequence Containers: implement data structures that can be accessed in a sequential manner.
- vector - is the same as dynamic arrays with the ability to resize itselve automatically when an element is inserted or deleted, with its storage being handled automatically by the container. Vector elements are placed in contiguous storage so that they can be accessed and traversed using iterators. In vectors, data is inserted at the end. Inserting at the end takes differential time, as sometimes the array may need to be extended. Removing the last element takes only constant time because no resizing happens. Inserting and erasing at the beginning or in the middle is linear in time.
- list - is a sequence container that allows non-contiguous memory allocation. As compared to the vector, the list has slow traversal, but once a position has been found, insertion and deletion are quick (constant time). Normally, when we say a List, we talk about a doubly linked list.
- deque - Double-ended queues are sequence containers with the feature of expansion and contraction on both ends. They are similar to vectors, but are more efficient in case of insertion and deletion of elements. Unlike vectors, contiguous storage allocation may not be guaranteed.
- array - is a class based alternative to common arrays from C-language. It knows its size and cannot decay into a pointer.
- forward_list - implements singly linked list. The drawback of a forward list is that it cannot be iterated backward and its individual elements cannot be accessed directly.
- Container Adaptors: provide a different interface for sequential containers.
- queue - Queues are a type of container adaptors that operate in a first in first out (FIFO) type of arrangement. Elements are inserted at the back (end) and are deleted from the front. Queues use an encapsulated object of deque or list (sequential container class) as its underlying container, providing a specific set of member functions to access its elements.
- priority_queue - A C++ priority queue is a type of container adapter, specifically designed such that the first element of the queue is either the greatest or the smallest of all elements in the queue, and elements are in non-increasing or non-decreasing order (hence we can see that each element of the queue has a priority). In C++ STL, the top element is always the greatest by default. We can also change it to the smallest element at the top. Priority queues are built on the top of the max heap and use an array or vector as an internal structure. In simple terms, STL Priority Queue is the implementation of the Heap Data Structure. Heaps are used in graph algorithms like Dijkstra’s algorithm and Prim’s algorithm for finding the shortest paths and minimum spanning trees.
- stack - Stacks are a type of container adaptors with LIFO(Last In First Out) type of working, where a new element is added at one end (top) and an element is removed from that end only. Stack uses an encapsulated object of either vector or deque (by default) or list (sequential container class) as its underlying container, providing a specific set of member functions to access its elements.
- Associative Containers: implement sorted data structures that can be quickly searched (O(log n) complexity).
- set - Sets are a type of associative container in which each element has to be unique because the value of the element identifies it (the value is a key). The values are stored in a specific sorted order i.e. either ascending or descending. They are implemented as BST (Binary Search Trees).
- multiset - A multiset is a container in C++ that allows you to store multiple occurrences of the same value in a sorted order. It is part of the C++ Standard Template Library (STL) and is implemented as a Balanced Binary Search Tree.
- map - Maps are associative containers that store elements in a mapped fashion. Each element has a key value and a mapped value. No two mapped values can have the same key values. Maps are implemented by self-balancing search trees. In C++ STL it uses Red-Black Tree.
- multimap - Multimap is similar to a map with the addition that multiple elements can have the same keys. Also, it is NOT required that the key-value and mapped value pair have to be unique in this case. One important thing to note about multimap is that multimap keeps all the keys in sorted order always.
- Unordered Associative Containers: implement unordered data structures that can be quickly searched
- unordered_set - An unordered_set is an unordered associative container implemented using a Hash Table where keys are hashed into indices of a hash table so that the insertion is always randomized.
- unordered_multiset - The unordered_multiset in C++ STL is an unordered associative container that works similarly to an unordered_set. The only difference is that we can store multiple copies of the same key in this container. It is also implemented using a Hash Table so the time complexity of the operations is O(1) on average which can go up to linear time O(n) in the worst case. Internally when an existing value is inserted, the data structure increases its count which is associated with each value. A count of each value is stored in unordered_multiset, it takes more space than unordered_set (if all values are distinct).
- unordered_map - is an associated container that stores elements formed by the combination of a key value and a mapped value. The key value is used to uniquely identify the element and the mapped value is the content associated with the key. Both key and value can be of any type predefined or user-defined. In simple terms, an unordered_map is like a data structure of dictionary type that stores elements in itself. It contains successive pairs (key, value), which allows fast retrieval of an individual element based on its unique key. Internally unordered_map is implemented using Hash Table, the key provided to map is hashed into indices of a hash table which is why the performance of data structure depends on the hash function a lot but on average, the cost of search, insert, and delete from the hash table is O(1).
- unordered_multimap - the same as unordered_map, but allows duplicates of key-value pairs.
What is an Iterator in STL?
An iterator is an object (like a pointer) that points to an element inside the container. We can use iterators to move through the contents of the container. They can be visualized as something similar to a pointer pointing to some location and we can access the content at that particular location using them.
There are 5 types of iterators:
- Input Iterators: They are the weakest of all the iterators and have very limited functionality. They can only be used in a single-pass algorithms, i.e., those algorithms which process the container sequentially, such that no element is accessed more than once.
- Output Iterators: Just like input iterators, they are also very limited in their functionality and can only be used in single-pass algorithm to modify the elements.
- Forward Iterators: They are higher in the hierarchy than input and output iterators, and contain all the features present in these two iterators. But, as the name suggests, they also can only move in a forward direction one step at a time.
- Bidirectional Iterators: They have all the features of forward iterators along with the fact that they overcome the drawback of forward iterators, as they can move in both the directions, that is why their name is bidirectional.
- Random-Access Iterators: They are the most powerful iterators. They are not limited to moving sequentially, as their name suggests, they can randomly access any element inside the container. They are the ones whose functionality are same as pointers.
| STL Container | Types of iterators supported |
| Vector | Random-Access |
| List | Bidirectional |
| Deque | Random-Access |
| Map | Bidirectional |
| Multimap | Bidirectional |
| Set | Bidirectional |
| Multiset | Bidirectional |
| Unordered-Map | Forward |
| Unordered-Multimap | Forward |
| Unordered-Set | Forward |
| Unordered-Multiset | Forward |
Give an overview of Algorithms in STL.
The header algorithm defines a collection of functions specially designed to be used on a range of elements. They act on containers and provide means for various operations for the contents of the containers.
- Sorting - There is a built-in function in C++ STL by the name of sort(). This function internally uses IntroSort. In more details it is implemented using hybrid of QuickSort, HeapSort and InsertionSort. By default, it uses QuickSort but if QuickSort is doing unfair partitioning, it switches to HeapSort and when the array size becomes really small, it switches to InsertionSort.
- Searching - Binary Search in a sorted array binary_search(startaddress, endaddress, valuetofind).
- Partition Operations - C++ has a class in its STL algorithms library which allows us easy partition algorithms using certain built-in functions. Partition refers to act of dividing elements of containers depending upon a given condition.
Partition operations :- partition(beg, end, condition) - This function is used to partition the elements on basis of condition mentioned in its arguments.
- is_partitioned(beg, end, condition) - This function returns boolean true if container is partitioned else returns false.
- Some other important STL algorithms:
- reverse(first_iterator, last_iterator) – To reverse a sequencial container. ( if ascending -> descending OR if descending -> ascending)
- *max_element (first_iterator, last_iterator) – to find the maximum element of a container.
- *min_element (first_iterator, last_iterator) – to find the minimum element of a container.
- accumulate(first_iterator, last_iterator, initial value of sum) – does the summation of container elements.
- count(first_iterator, last_iterator,x) – To count the occurrences of x in a container.
- find(first_iterator, last_iterator, x) – Returns an iterator to the first occurrence of x in a container and points to end of the container ((name_of_vector).end()) if element is not present in it.
- lower_bound(first_iterator, last_iterator, x) – returns an iterator pointing to the first element in the range [first,last) which has a value not less than ‘x’.
- upper_bound(first_iterator, last_iterator, x) – returns an iterator pointing to the first element in the range [first,last) which has a value greater than ‘x’.
- next_permutation(first_iterator, last_iterator) – modifies the container to its next permutation.
- prev_permutation(first_iterator, last_iterator) – modifies the container to its previous permutation.
- distance(first_iterator,desired_position) – It returns the distance of desired position from the first iterator.This function is very useful while finding the index.
What is Concurrency in Programming?
In computer science, concurrency is the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the outcome.
What is the difference between Concurrency and Parallelism?
Concurrency is about multiple tasks which start, run, and complete in overlapping time periods, in no specific order. Parallelism is about multiple tasks or subtasks of the same task that literally run at the same time on a hardware with multiple computing resources like multi-core processor.
Elist Errors and Risks associated with Concurency.
Concurrent multithreading applications need to be carefully designed as it is prone to many errors leading to undefined behaviour. Some of these errors are:
- Race Conditions - happen when two or more threads access shared data concurrently leading to the undefined behaviour.
- Deadlocks - refer to the situation where two or more threads are blocked forever waiting for each other. The careful synchronization is essential to prevent deadlocks.
- Starvation - is the condition where a thread is unable to gain regular access to the shared resources.
Enlist Libraries and Instruments for realizing Concurrency in C++.
In C++, the support for concurrency was first added in C++ 11 to improve the performance of the program and enable multitasking. The components such as thread, mutex, memory model, and various synchronization primitives were added as the part of Concurrency Support Library.
- Threads - Threads are the basic unit of multitasking. The concurrent execution of the tasks is done by creating multiple threads in a multithreaded environment. The C++ provides a
threadlibrary for creating and managing threads. - Thread Synchronization - Thread synchronization can be done using the following components provided in C++:
- Mutex and Locks - The Mutual Exclusion and Locks are used to protect shared resources. Ensures that only one thread accesses critical sections at a time. C++ have
mutexheader file which contains thestd::mutexclasses. - Condition Variables - are used for thread synchronization by acting as a flag that notifies the threads when the shared resources are free. C++ have
condition_variableheader that contains thecondition_variableobject. - Futures and Promises -
futureandpromiseare used for asynchronous task execution. This method is only viable when thread tasks are independent of each other. - Semaphores - are also a synchronization primitive that counts the number of threads accessing the shared resource. If this count exceeds the number of accesses available, the semaphore will block the access till the count is freed.
- Mutex and Locks - The Mutual Exclusion and Locks are used to protect shared resources. Ensures that only one thread accesses critical sections at a time. C++ have
- Thread Pool - normal threads have to be manually managed regarding their lifecycle and the associated functions. Thread Pools contain automatically managed threads with an API that allows adding tasks into a work queue of pending tasks. The pool feeds from the queue as soon as slot is available.
std::futurecan be used to wait for tasks to be completed. - Atomic Operation - indivisible operation. It cannot be observed half-done from any thread in the system. If one thread writes to an atomic object while another thread reads from it, the behavior is well-defined. Atomics allow writting lock-free multithreading, meaning there is no need to use any synchronization primitive.
- Coroutines - A coroutine is a function that can suspend execution to be resumed later. Coroutines are stackless: they suspend execution by returning to the caller and the data that is required to resume execution is stored separately from the stack. This allows for sequential code that executes asynchronously (e.g. to handle non-blocking I/O without explicit callbacks), and also supports algorithms on lazy-computed infinite sequences and other uses.
Give an example of a Race Condition in C++.
Following code shows a situation of race condition if thread synchronization by locking mutex is not present:
#include <iostream>
#include <thread>
#include <mutex>
void sharedPrint(char c, int v, std::mutex& theMutex) {
//theMutex.lock(); // if uncommented, synchronises the access from different threads
std::cout << c << v << "\n";
//theMutex.unlock();
}
// function for sequence
void printingLoop(char d, int a, std::mutex& theMutex) {
for (int i = 1; i <= a; i++) {
sharedPrint(d, i, theMutex);
}
}
int main()
{
std::mutex localMutex;
std::thread threadA(printingLoop, 'A', 10, std::ref(localMutex));
std::thread threadB(printingLoop, 'B', 10, std::ref(localMutex));
std::thread threadC(printingLoop, 'C', 10, std::ref(localMutex));
threadA.join();
threadB.join();
threadC.join();
return 0;
}
Enlist types of Mutexes.
There are three basic types of mutual exclusion:
std::mutex– is a synchronization primitive that can be used to protect shared data from being simultaneously accessed by multiple threads. Mutex offers exclusive, non-recursive ownership semantics:- A calling thread owns a mutex from the time that it successfully calls either
lockortry_lockuntil it callsunlock. - When a thread owns a mutex, all other threads will block (for calls to
lock) or receive a false return value (fortry_lock) if they attempt to claim ownership of the mutex. - A calling thread must not own the mutex prior to calling lock or try_lock.
The behavior of a program is undefined if a mutex is destroyed while still owned by any threads, or a thread terminates while owning a mutex. This type of mutex can be locked only once even by an owning thread, otherwise Deadlock condition arises.
- A calling thread owns a mutex from the time that it successfully calls either
std::recursive_mutex– is a synchronization primitive that can be used to protect shared data from being simultaneously accessed by multiple threads.recursive_mutexoffers exclusive, recursive ownership semantics:- A calling thread owns a
recursive_mutexfor a period of time that starts when it successfully calls eitherlockortry_lock. During this period, the thread may make additional calls tolockortry_lock. The period of ownership ends when the thread makes a matching number of calls tounlock. - When a thread owns a
recursive_mutex, all other threads will block (for calls tolock) or receive a false return value (fortry_lock) if they attempt to claim ownership of therecursive_mutex. - The maximum number of times that a
recursive_mutexmay be locked is unspecified, but after that number is reached, calls to lock will throwstd::system_errorand calls totry_lockwill return false.
The behavior of a program is undefined if a recursive_mutex is destroyed while still owned by some thread.
- A calling thread owns a
std::shared_mutex- is a synchronization primitive that can be used to protect shared data from being simultaneously accessed by multiple threads. In contrast to other mutex types which facilitate exclusive access, a shared_mutex has two levels of access:- shared - several threads can share ownership of the same mutex.
- exclusive - only one thread can own the mutex.
If one thread has acquired the exclusive lock (through
lock,try_lock), no other threads can acquire the lock (including the shared).
If one thread has acquired the shared lock (throughlock_shared,try_lock_shared), no other thread can acquire the exclusive lock, but can acquire the shared lock.
Only when the exclusive lock has not been acquired by any thread, the shared lock can be acquired by multiple threads.
Within one thread, only one lock (shared or exclusive) can be acquired at the same time.
Shared mutexes are especially useful when shared data can be safely read by any number of threads simultaneously, but a thread may only write the same data when no other thread is reading or writing at the same time.
Enlist types of RAII(Resource Acquisition Is Initialization) Wrappers of Mutex Locks.
There are mainly three types of such wrappers:
std::unique_lock- is a general-purpose mutex ownership wrapper allowing deferred locking, time-constrained attempts at locking, recursive locking, transfer of lock ownership, and use with condition variables. The classunique_lockis movable, but not copyable.std::shared_lock- is a general-purpose shared mutex ownership wrapper allowing deferred locking, timed locking and transfer of lock ownership. Locking ashared_locklocks the associated shared mutex in shared mode (to lock it in exclusive mode,std::unique_lockcan be used). The shared_lock class is movable, but not copyable.std::scoped_lock- is a mutex wrapper that provides a convenient RAII-style mechanism for owning zero or more mutexes for the duration of a scoped block.
When ascoped_lockobject is created, it attempts to take ownership of the mutexes it is given. When control leaves the scope in which thescoped_lockobject was created, thescoped_lockis destructed and the mutexes are released. If several mutexes are given, deadlock avoidance algorithm is used as if bystd::lock.
Thescoped_lockclass is non-copyable.
Give some examples of Deadlocks and how to avoid them.
The following code will deadlock since std::mutex can be locked at most once:
#include <mutex>
std::mutex globalMutex;
void function1() {
std::unique_lock localLock(globalMutex);
// bussiness logic...
}
void function2() {
std::unique_lock localLock(globalMutex);
// bussiness logic...
function1(); // here will be a DEADLOCK
}
One can avoid the deadlock in the code above by using std::recursive_mutex instead of std::mutex. Another possible scenario of a Deadlock is as follows:
std::mutex localMutex1, localMutex2, localMutex3;
void threadA() {
// this thread acquires locks on localMutex1 and localMutex2 and waits for ThreadB to release localMutex3
std::unique_lock localLock1{localMutex1}, localLock2{localMutex2}, localLock3{localMutex3};
}
void threadB() {
// this thread acquires lock on localMutex3 and waits for the ThreadA to release localMutex2
std::unique_lock localLock3{localMutex3}, localLock2{localMutex2}, localLock1{localMutex1};
}
In this kind of situation deadlocks can be avoided by maintaning a globaly consistent order, so that one thread always wins, like in the following example:
std::mutex localMutex1, localMutex2, localMutex3;
void threadA() {
// no deadlocks
std::unique_lock localLock1{localMutex1}, localLock2{localMutex2}, localLock3{localMutex3};
}
void threadB() {
// no deadlocks
std::unique_lock localLock1{localMutex1}, localLock2{localMutex2}, localLock3{localMutex3};
}
Or alternatively, if globaly consistent order is not possible, one can use std::scoped_lock as follows:
std::mutex localMutex1, localMutex2, localMutex3;
void threadA() {
// no deadlocks
std::scoped_lock localLock{localMutex1, localMutex2, localMutex3};
}
void threadB() {
// no deadlocks
std::scoped_lock localLock{localMutex3, localMutex2, localMutex1};
}
What is a Condition Variable in C++?
A condition variable is a synchronization primitive that allows multiple threads to wait until an (arbitrary) condition becomes true. The standard library defines the class std::condition_variable in the header condition_variable which has the following member functions:
- wait(): takes a reference to a
std::unique_lockthat must be locked by the caller as an argument, unlocks the mutex and waits for the condition variable. - notify_one(): notify a single waiting thread, mutex does not need to be held by the caller.
- notify_all(): notify all waiting threads, mutex does not need to be held by the caller.
An example of application of condition variables are worker queues:
// here a function that fills the worker queue is defined
std::mutex globalMutex;
std::condition_variable conditionVar;
std::vector<int> taskQueue;
void pushWork(int task) {
{
std::unique_lock localLock{globalMutex};
taskQueue.push_back(task);
}
conditionVar.notify_one(); // a condition variable notifies working thread that the queue has a new task
}
// here a function of a working thread is defined
void workerThread() {
std::unique_lock localLock{globalMutex};
while (true) {
while (!taskQueue.empty()) {
int task = taskQueue.back();
taskQueue.pop_back();
localLock.unlock();
// bussiness logic here ...
localLock.lock();
}
conditionVar.wait(localLock); // wait for notification here
}
}
Give an example of using an Atomic Variable in Concurrency.
The following code represents a possible use case for an Atomic Variable:
#include <atomic>
#include <thread>
int main() {
std::atomic<unsigned> atomicValue = 0;
thread threadA([]() {
for (size_t i = 0; i < 10; ++i)
atomicValue.fetch_add(1); // thread safe atomic increment
});
for (size_t i = 0; i < 10; ++i)
atomicValue.fetch_add(1); // thread safe atomic increment
threadA.join();
// atomicValue will contain 20
}
Give an example of a Use Case for Futures and Promises.
A possible Use Case for Futures and Promises would be passing of data between threads (an alternative to wait-notify pattern implemented by condition variables):
#include <iostream>
#include <thread>
#include <future>
void modifyMessage(std::promise<std::string> && thePromise, std::string theMessage)
{
std::this_thread::sleep_for(std::chrono::milliseconds(4000)); // simulate work
std::string modifiedMessage = theMessage + " has been modified";
thePromise.set_value(modifiedMessage);
}
int main()
{
std::string messageToThread = "My Message";
std::promise<std::string> promise;
std::future<std::string> future = promise.get_future();
// start thread and pass promise as argument
std::thread threadA(modifyMessage, std::move(promise), messageToThread);
std::cout << "Original message from main(): " << messageToThread << std::endl;
std::string messageFromThread = future.get();
std::cout << "Modified message from thread(): " << messageFromThread << std::endl;
threadA.join();
return 0;
}